





Категория: Инструкции
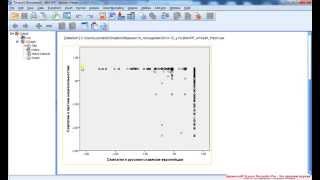
Вы увидите четыре отдельных отчетливых группировки точек, три из них в нижней половине диаграммы и одну в верхнем правом углу. Следовательно, переменные kalorien (калории) и kosten (расходы), явно распадаются на четыре различных кластера по сортам пива.
Сорта пива, которые по значениям двух рассмотренных переменных похожи друг на друга, принадлежат к одному кластеру; сорта пива, находящиеся в различных кластерах, не похожи друг на друга. Решающим критерием для определения схожести и различия двух сортов пива является расстояние между точками на диаграмме рассеяния, соответствующими этим сортам.
Самой распространенной мерой для определения расстояния между двумя точками на плоскости, образованной координатными осями х и у, является евклидова мера:
Где x1. и хn – координаты первой точки, у: и уn – координаты второй точки.
В соответствии с этой формулой расстояние между сортами пива Budweisei Heineken составляет:
Это расстояние лишь незначительно превосходит то, которое получилось бы, если бы для расчета была взята только одна переменная – kalorien (калории):
Данный эффект можно объяснить тем, что уровни значений переменных kalorien (калории) и kosten (расходы) очень сильно отличаются друг от друга: у переменной kosten (расходы) значения меньше 1, а у переменной kalorien (калории) больше 100. Согласно формуле евклидовой меры, переменная, имеющая большие значения, практически полностью доминирует над переменной с малыми значениями.
Решением этой проблемы является рассмотренное в главе 19.1 z-преобразование (стандартизация) значений переменных. Стандартизация приводит значения всех преобразованных переменных к единому диапазону значений, а именно от -3 до +3.
Если Вы произведете такое преобразование для переменных kalorien (калории) и kosten (расходы), то для пива Budweiser получите стандартизованные значения равные 0.400 и – 0.469 соответственно, а для пива Heineken стандартизированные значения 0.649 и 1.848 соответственно.
Тогда расстояние между двумя сортами пива получится равным:
Таким образом, при помощи диаграммы рассеяния для двух переменных: kalorien (калории) и kosten (расходы), мы провели самый простой кластерный анализ. Мы выбрали такой вид графического представления, с помощью которого можно было бы отчетливо распознать группирование в кластеры (четыре в нашем случае).
К сожалению, столь отчетливая картина отношений между переменными, как в приведенном примере, встречается очень редко. Во-первых, структуры кластеров, если вообще таковые имеются, не так четко разделены, особенно при наличии большого количества наблюдений. Скорее наоборот, кластеры размыты и даже проникают друг в друга. Во-вторых, как правило, кластерный анализ проводится не с двумя, а с намного большим количеством переменных.
При кластерном анализе с тремя переменными можно ввести еще одну ось – ось z и рассматривать размещение наблюдений, а также проводить расчет расстояния по формуле евклидовой меры в трехмерном пространстве.
При наличии более трех переменных определение расстояния между двумя точками х и у в любом n-мерном пространстве для математиков не представляет особого труда. Формула Евклида в таких случаях приобретает следующий вид:
Наряду с евклидовой мерой расстояния, SPSS предлагает и другие дистанционные меры, а также меры подобия. Так что кластерный анализ можно проводить не только с переменными, относящимися к интервальной шкале, как в приведенном случае, но и с дихотомическими переменными, к примеру. В таком ситуации применяется уже другие дистанционные меры и меры подобия (см. разд. 20.3).
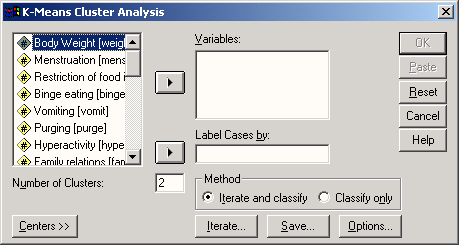
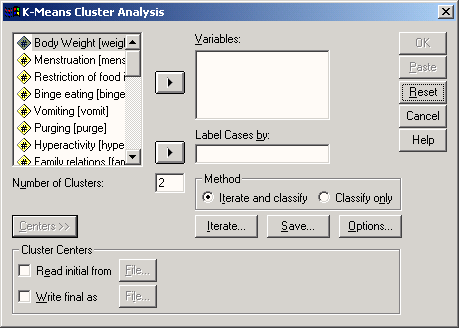
При проведении кластерного анализа отдельные кластеры могут формироваться при помощи пошагового слияния, для которого существует ряд различных методов (см. разд. 20.4). Важную роль играют иерархические и партиционные методы, причем последние применяются в подавляющем большинстве случаев. Оба эти метода можно задействовать, если пройти через меню Analyze (Анализ) › Classify (Классифицировать)
Они помещены в этом меню под именами Hierarchical Cluster… (Иерархический кластер) и K-Means Cluster… (Кластерный анализ методом к-средних).
Рассмотрим сначала иерархический кластерный анализ, причем начнем с простого примера с 17 сортами пива.









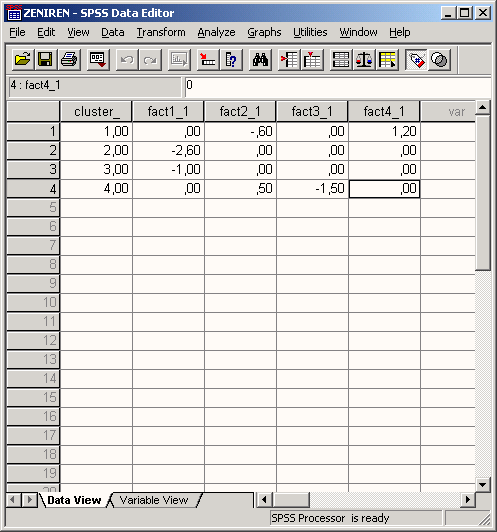
Программа SPSS позволяет проводить кластерный анализ не только объектов, но и переменных. В последнем случае кластерный анализ может выступать как более простой и нередко более эффективный аналог факторного анализа.
В данном разделе нами будет рассмотрен алгоритм реализации в программе SPSS иерарического агломеративного кластерного анализа. Рассмотрим его реализацию поэтапно.
1. Запустите программу SPSS при помощи значка на рабочем столе или команды Пуск→Программы→ SPSS for Windows → SPSS 11.5 for Windows. В открывшемся диалоговом окне щелкните на кнопку Сancel (Отмена).
2. Создайте новый файл данных или откройте существующий.
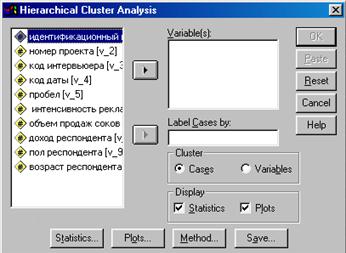
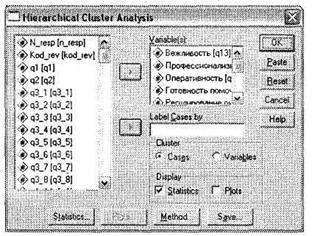
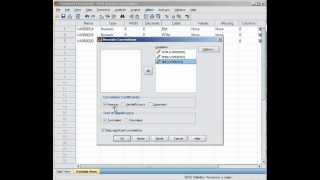
В меню Analyze (Анализ) выберите команду Classifi→Hierarchical Cluster (Классификация→Иерархическая кластеризация). На экране появится диалоговое окно Hierarchical Cluster Analysis (Иерархический кластерный анализ), показанное на рисунке 4.2.
Рис. 4.2 Диалоговое окно Hierarchical Cluster Analysis
Структура окна Hierarchical Cluster Analysis типична для большинства диалоговых окон SPSS. Слева находится список переменных текущего файла данных. Выделите переменные, с помощью которых будет осуществляться процесс кластеризации, и при помощи кнопки со стрелкой перенесите их в поле Variable(s) (Переменные). В поле Label Cases by (Различать объекты по) с помощью кнопки со стрелкой переносится переменная, идентифицирующая объекты.
В поле Cluster (Кластеризация) предусмотрены два переключателя (Объекты) и (Переменные). Маркером помечают один из вариантов процедуры кластеризации. В случае кластеризации переменных поле Label Cases by (Различать объекты по) останется пустым.
В нижней части диалогового окна расположены четыре кнопки, предназначенные для задания дополнительных параметров команды.
4. Настройка кнопки Statistics (Статистики)
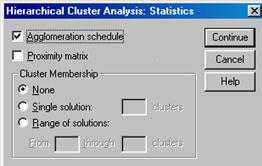
При щелчке по кнопке Statistics (Статистики) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Statistics (Иерархический кластерный анализ: Статистики), представленное на рис. 4.3.
Рис. 4.3. Диалоговое окно Hierarchical Cluster Analysis: Statistics
Флажок Agglomeration Schedule (Последовательность слияния) по умолчанию установлен, обеспечивая включение в результаты стандартного компонента вывода кластерного анализа. Флажок Proximity Matrix (Матрица сходства) предназначен для отображения информации о расстояниях между объектами и кластерами. Использование матрицы удобно лишь для небольших файлов данных. Группа Cluster Membership (Кластеры в решении) состоит из трех переключателей, описанных ниже.
None (Нет) - в выводимые результаты включаются все кластеры. Этот вариант установлен по умолчанию.
Single solution (Единственное решение) - позволяет определить точное число выводимых кластеров.
Range of solution (Диапазон решений) - обеспечивает вывод нескольких решений с разным числом кластеров. Так, если ввести в поле (От) число 2. А вполе (До) число 6, то в выводимые результаты будут включены все решения с количеством кластеров от 2 до 6.
5. Настройка кнопки Plots (Диаграммы)
При щелчке по кнопке Plots (Диаграммы) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Plots (Иерархический кластерный анализ: Диаграммы), представленное на рис. 4.4.

Рис. 4.4. Диалоговое окно Hierarchical Cluster Analysis: Plots
Флажок Dendrogram (Дендрограмма) позволяет включить в выводимые результаты дендрограмму.
6. Настройка кнопки Method (Метод)
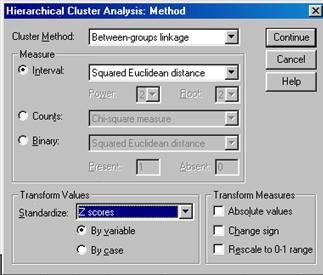
При щелчке по кнопке Method (Метод) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Method (Иерархический кластерный анализ: метод), представленное на рис. 4.5.
Рис. 4.5. Диалоговое окно Hierarchical Cluster Analysis: Method
В данном окне раскрывается список Cluster Method (Метод кластеризации). который содержит возможные методы кластеризации объектов, среди них:
Between-groups linkage - метод "межгруппового связывания".
Within- groups linkage - метод "внутригруппового связывания".
Nearest neighbor - метод "одиночного связывания".
Furthest neighbor - метод "полного связывания"
Centroid clustering - метод "центроидной кластеризации".
Wards method - метод Варда.
В раскрывающемся списке Interval (Интервал) по умолчанию выбран пункт Squared Euclidean distance (Квадрат Евклидова расстояния). Это означает, что расстояние между объектами вычисляется как разность квадратов соответствующих переменных этих объектов. Возможен выбор и других мер сходства.
Процедура стандартизации исходных данных выбирается в раскрывающемся списке Standardize (Стандартизация). По умолчанию выбран пункт None (Нет). Однако в случаях, когда стандартизация необходима чаще всего выбирают пункт Z scores (z-шкала).
В группе Transofm Measures (Преобразование значений) имеется три флажка, позволяющих изменить значения переменных: Absolute values (Абсолютные значения), Change Sign (Смена знаков), Rescale to 0-1 (Свести к интервалу 0-1).
7. Настройка кнопки Save (Сохранить)
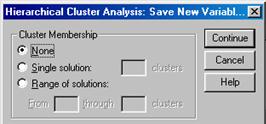
При щелчке по кнопке Save (Сохранить) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Save New Variables (Иерархический кластерный анализ: сохранение новых переменных), представленное на рис. 4.6.
Рис. 4.6. Диалоговое окно Hierarchical Cluster Analysis:
Save New Variables
С помощью этого окна можно создавать новые переменные значения которых будут хранить вычисленные статистические величины. Если установлен переключатель None (Нет), то никакого сохранения в процессе анализа не производится. В противном случае при выполнении анализа будут созданы переменные, которые окажутся в конце файла данных. После установления соответствующих настроек необходимо с помощью щелчка по кнопке Continue (продолжить) возвратиться в основное диалоговое окно Hierarchical Cluster Analysis.
8. Запуск процедуры выполнения кластерного анализа осуществляется в диалоговом окне окно Hierarchical Cluster Analysis щелчком по кнопке ОК. Кнопка Reset (Сброс) позволяет корректировать настройки.
1. В чем состоит принципиальное отличие методов многомерных классификаций от комбинационных группировок?
2. Назовите область применения кластерного анализа в маркетинге?
3. Раскройте сущность иерархических агломеративных и дивизимных методов кластерного анализа? В чем их достоинства и недостатки?
4. Раскройте сущность итеративных методов кластерного анализа? В чем их достоинства и недостатки?
5. Раскройте алгоритм реализации иерархического агломеративного кластерного анализа?
6. Что иллюстрирует дендрограмма кластеризации объектов в кластерном анализе?
7. Назовите основные критерии качества классификации объектов в кластерном анализе и их практическую значимость?
8. Раскройте поэтапно алгоритм реализации кластерного анализа в SPSS?
1. Анурин В. Муромкина И. Евтушенко Е. Маркетинговые исследования потребительского рынка. - СПб. Питер, 2006. - 260 с.
2. Бернс Э. Буш Р. Основы маркетинговых исследований с использованием Excel. - СПб. Вильямс, 2006.
3. Белявский И. Маркетинговое исследование: информация, анализ, прогноз. М. Финансы и статистика, 2001.
4. Власова М.Л. Социологические методы в маркетинговых исследований. - М. ГУ ВШЭ, 2006.
5. Гмурман В. Е. Теория вероятностей и математическая статистика: Учеб. пособие для вузов. - 8-е изд. - М. Высшая школа, 2002.
6. Жамбю М. Иерархический кластер-анализ и соответствия. - М. Финансы и статистика, 1988. - 342 с.
7. Иберла К. Факторный анализ. М. Статистика, 1980. - 398 с.
8. Коротков А. В. Маркетинговые исследования. - М. ЮНИТИ-ДАНА, 2005. - 304 с.
9. Мандель И. Д. Кластерный анализ. - М. Финансы и статистика, 1988. - 176 с.
10. Малхотра К. Маркетинговые исследования и эффективный анализ статистических данных. - М. Диасофт, 2002.
11. Малхотра К. Маркетинговые исследования: Практическое руководство. 3-е изд. М. Вильямс, 2002.
12. Многомерный статистический анализ в экономике: Учеб. пособие для вузов / Под ред. В. Н. Тамашевича. - М. ЮНИТИ-ДАНА, 1999. - 598 с.
13. Математические методы в экономике: Учебник / Под общ. ред. д.э.н. проф. А.В Сидоровича, МГУ им. М.В. Ломоносова. - М. Издательство "Дом и Сервис", 2001.
14. Моосмюллер Г. Ребик Н.Н. Маркетинговые исследования с SPSS. - М. Инфра-М, 2007. - 160 с.
15. Наследов А. Д. SPSS: Компьютерный анализ в психологии и социальных науках. - СПб. Питер, 2007. - 416 с.
16. Пиотровский А. Денисов А. Кластерный анализ как инструмент подготовки эффективных маркетинговых решений // Практический маркетинг. - 2001. - №5.
17. Общая теория статистики: Учебное пособие / Под ред. А.А. Спирина, О.Э. Башиной – М. Финансы и статистика, 1999.
18. Черчилль Г.А. Маркетинговые исследования. - СПб. Питер, 2007.
© studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам
SPSS 19, Профессиональный статистический анализ данных, Наследов А. 2011.
Книга представляет собой практическое руководство по анализу данных с помощью самой мощной и популярной программы статистической обработки информации – SPSS версии 19. В издании подробно описываются основы работы с пакетом SPSS, рассматривается большинство методов обработки и анализа данных, а также способов табличного и графического представления полученных результатов. Материал книги организован таким образом, чтобы удовлетворить запросы как новичка, впервые приступающего к анализу данных на компьютере, так и опытного исследователя, желающего воспользоваться самыми современными методами. Основное содержание глав составляют пошаговые инструкции по реализации различных видов математико-статистического анализа в SPSS. Особое внимание уделяется получаемым результатам и их интерпретации. В конце книги приведен глоссарий, содержащий определения большинства статистических терминов. Издание адресовано исследователям в области статистики, маркетинга, социологии, психологии, а также широкому кругу читателей, желающих воспользоваться программой SPSS для профессионального анализа данных.
Версии SPSS.
По всем параметрам SPSS является сложным и мощным статистическим пакетом. Однако, несмотря на сложность, средства взаимодействия входящих в пакет программ с пользователем весьма дружественны. С помощью пакета SPSS можно проводить практически любой анализ данных, а последние версии программы находят применение в самых разных научных областях и в мире бизнеса.
Основой для данной книги послужила русифицированная версия 19.0 пакета IBM SPSS Statistics, распространяемая с сентября 2010 года. Говоря точнее, снимки экрана, присутствующие в книге, соответствуют русифицированной версии 19.0. Однако почти весь изложенный материал может быть с успехом применен и к более ранним версиям, начиная с SPSS 9.0. Основные отличия будут иметь место в интерфейсе программ: названиях диалоговых окон, их виде и т. п. Кроме того, начиная с версии SPSS 13.0 более совершенными стали графические возможности программы. Для отечественного пользователя программы наиболее значительное новшество введено начиная с версии SPSS 12.0 — стала доступной русифицированная версия интерфейса и окон вывода результатов.
Содержание
Предисловие
Глава 1. Введение
Обработка данных на компьютере
Необходимые знания
Версии SPSS
Содержание книги
Файлы примеров
Структура глав и элементы описания
Глава 2. Общий обзор SPSS
Запуск программы
Кнопки и другие элементы управления
Настройка параметров программы
Окна программы
Окно редактора командного языка Syntax
Окно вывода и его редактирование
Сохранение, экспорт, перенос и печать результатов
Глава 3. Создание и редактирование файлов данных
Структура файла данных
Ввод данных
Редактирование данных
Пример файла данных
Глава 4. Управление данными
Знакомство с возможностями управления данными
Получение информации о файле
Обработка пропущенных значений
Преобразование данных
Выбор наблюдений для анализа
Перекодировка в новую переменную
Перекодирование существующей переменной
Сортировка наблюдений
Объединение данных разных файлов
Агрегирование данных
Реструктурирование данных
Глава 5. Диаграммы
Графика в программе SPSS
Настройка диаграмм
Команды построения диаграмм
Редактирование диаграмм
Выход из программы
Глава 6. Частоты
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 7. Описательные статистики
Пошаговый алгоритм вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 8. Таблицы сопряженности и критерий хи-квадрат
Таблицы сопряженности
Критерий независимости хи-квадрат
Пошаговый алгоритм вычислений
Представление результатов
Терминология, используемая при выводе
Завершение анализа и выход из программы
Глава 9. Корреляции
Понятие корреляции
Дополнительные сведения
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 10. Средние значения
Пошаговый алгоритм вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 11. Сравнение двух средних и t-критерий
Уровень значимости
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 12. Непараметрические критерии
Параметрические и непараметрические критерии
Пошаговые алгоритмы и результаты вычислений
Завершение анализа и выход из программы
Глава 13. Однофакторный дисперсионный анализ
Пошаговые алгоритмы вычислений
Представление результатов
Терминология
Завершение анализа и выход из программы
Глава 14. Многофакторный дисперсионный анализ
Файлы данных для группы методов Общая линейная модель
Дисперсионный анализ с двумя факторами
Дисперсионный анализ с тремя и более факторами
Влияние ковариат
Пошаговые алгоритмы вычислений
Представление результатов
Терминология, используемая при выводе
Завершение анализа и выход из программы
Глава 15. Многомерный дисперсионный анализ
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 16. Дисперсионный анализ с повторными измерениями
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 17. Простая линейная регрессия
Простая регрессия
Оценка криволинейности
Пошаговые алгоритмы вычислений
Представление результатов
Терминология, используемая при выводе
Завершение анализа и выход из программы
Глава 18. Множественный регрессионный анализ
Уравнение множественной регрессии
Коэффициенты регрессии
Коэффициент детерминации и пошаговые методы
Условия получения приемлемых результатов анализа
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 19. Анализ надежности
Коэффициент альфа
Надежность половинного расщепления
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 20. Факторный анализ
Вычисление корреляционной матрицы
Извлечение факторов
Выбор и вращение факторов
Интерпретация факторов
Пошаговые алгоритмы вычислений
Представление результатов
Терминология, используемая при выводе
Завершение анализа и выход из программы
Глава 21. Кластерный анализ
Сравнение кластерного и факторного анализов
Этапы кластерного анализа
Кластерный анализ матрицы различий (сходства)
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 22. Дискриминантный анализ
Этапы дискриминантного анализа
Пошаговые алгоритмы вычислений
Представление результатов
Терминология, используемая при выводе
Завершение анализа и выход из программы
Глава 23. Многомерное шкалирование
Квадратная асимметричная матрица различий
Квадратная симметричная матрица различий
Модель индивидуальных различий
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глава 24. Логистическая регрессия
Математическое описание логистической регрессии
Пошаговые алгоритмы вычислений
Представление результатов
Терминология, используемая при выводе
Завершение анализа и выход из программы
Глава 25. Логлинейный анализ таблиц сопряженности
Понятие логлинейной модели
Логлинейный метод подбора модели
Пошаговые алгоритмы вычислений
Представление результатов
Завершение анализа и выход из программы
Глоссарий
Англо-русский словарь терминов
Литература.
Бесплатно скачать электронную книгу в удобном формате и читать:

Учебно-методическое пособие. — Сургут: Издательский центр СурГУ, 2010. – 60 с.
В пособии рассматриваются статистические методы, применяемые в социологии и политологии с помощью компьютерной программы SPSS. Пособие содержит подробные пошаговые инструкции по выполнению команд, необходимых для получения статистической информации.
Данное пособие окажет помощь студентам специальностей «Политология» и «Связи с общественностью» при работе с SPSS: в учёте и организации исходных данных, в выборе наиболее адекватного метода исследования, в вычислении статистических показателей, в проведении более глубокого анализа данных и интерпретации результатов исследований.
Введение
Обработка данных на компьютере. Подготовительный этап
Определение структуры данных
Запуск SPSS. Окна программы
Создание и редактирование файлов данных
Ввод данных
Управление данными
Выбор объектов для анализа
Перекодировка в новую переменную
Одномерный описательный анализ социологических данных. Построение частотных (линейных) распределений
Частоты
Описательные статистики
Взаимосвязь переменных
Двумерный анализ социологических данных. Парные распределения
Коэффициенты корреляции
Анализ множественных ответов
Анализ множественных ответов с применением категориального метода
Таблицы сопряжённости (парные распределения) вопросов с множественными ответами
Анализ взаимосвязей качественных и количественных переменных. Средние значения
Команда Т-test для сравнения двух независимых выборок
Однофакторный дисперсионный анализ
Регрессионный анализ
Парный регрессионный анализ
Множественный регрессионный анализ
Факторный анализ
Исследование структуры данных
Значения факторов
Кластерный анализ
Иерархический кластер-анализ
Кластерный анализ при большом количестве наблюдений (Кластерный анализ методом к-средних)
Заключение
Словарь основных терминов, используемых в процедурах прикладного социологического исследования