







Категория: Инструкции
План конспекта лекции
2. Выполнение программ на компьютере
3. Системы программирования
4. Структурная организация данных
5. Применение подпрограмм при программировании
6. Виды программирования
Процессор компьютера непосредственно служит для восприятия языка машинных команд. Поэтому можно сказать, что компьютер - исполнитель алгоритмов, переведенных на машинный язык. Компьютерная программа — последовательность инструкций, предназначенная для исполнения устройством управления вычислительной машины. Чаще всего образ программы хранится в виде исполняемого модуля (отдельного файла или группы файлов). Процесс создания компьютерных программ носит название программирование, а людей, занимающихся этим видом деятельности, называют программистами.
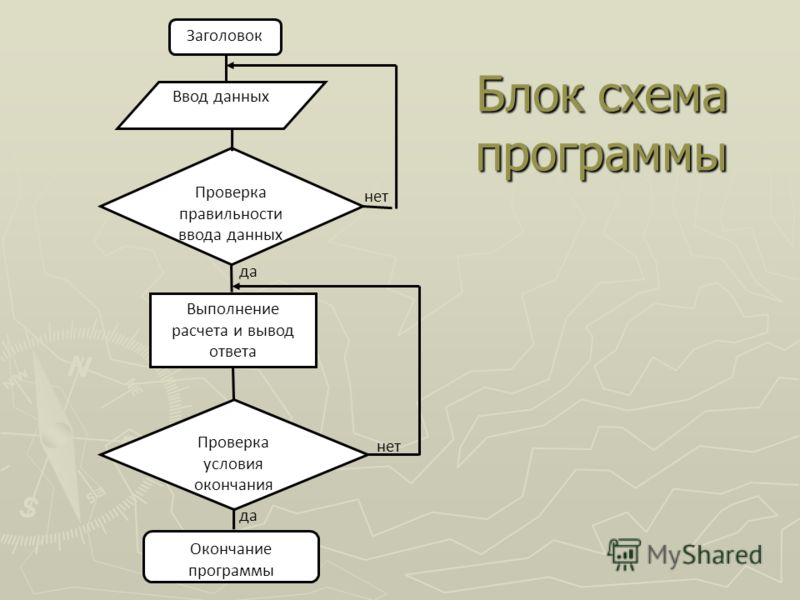
Выполнение программ на компьютере
Программирование на языке машинных команд - дело сложное, объясняется высокой трудоемкостью программирования непосредственно в машинных кодах. Программист должен знать числовые коды всех машинных команд и сам распределять память под команды программы и данные.
Первым значительным шагом представляется переход к языку Ассемблера. Программисту не надо было больше вникать в хитроумные способы кодирования команд на аппаратном уровне. Числовые коды операций заменились мнемоническими (словесными) обозначениями. Однако разные компьютеры с различными типами компьютеров требуют свой язык Ассемблера. Поэтому его называют машинно-зависимым или языком низкого уровня. Следует отметить, что простейшая операция взятия логарифма на языке Ассемблера составляет несколько сотен строк кода, в то время как на языке высокого уровня - всего одну строчку.
На смену языкам Ассемблера были разработаны языки программирования высокого уровня (ЯПВУ). Они машинно-независимы.
Язык высокого уровня - язык программирования, средства которого обеспечивают описание задачи в наглядном, легко воспринимаемом виде, удобном для программиста. Он не зависит от внутренних машинных кодов ЭВМ любого типа, поэтому программы, написанные на языках высокого уровня, требуют перевода в машинные коды программами транслятора.
Трансляция программы — преобразование программы, представленной на одном из языков программирования, в программу на другом языке и, в определённом смысле, равносильную первой.
Язык, на котором представлена входная программа, называется исходным языком, а сама программа — исходным кодом (модулем). Выходной язык называется целевым языком или объектным кодом (модулем).
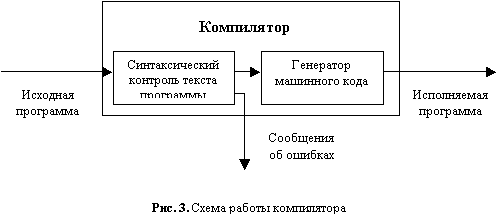
Трансляторы делятся на компиляторы и интерпретаторы.
Если цель трансляции - преобразование всего исходного текста программы на внутренний язык компьютера (т.е. получение некоторого нового кода), то такая трансляция называется также компиляцией.
При компиляции в память компьютера загружается программа-компилятор. Она воспринимает текст программы, написанной на языке высокого уровня, как исходную информацию, которая называется исходным модулем. После обработки исходный модуль, написанный на алгоритмическом языке, преобразуется в программу, состоящую из машинных команд. Это объектный модуль.
На следующем этапе компиляции выполняется специальная программа - редактор связей. Она подсоединяет к объектному модулю необходимые для его работы программные модули: все функции, процедуры, на которые он ссылается. Они выбираются из библиотеки подпрограмм соответствующей системы программирования и вставляются в объектный модуль. Этот процесс называется компоновкой (линкованием), и как его результат создается исполняемая программа. Ее также называют загрузочным модулем. Программа имеет расширение "ехе", загружается в память и выполняется.
Итак, при компиляции исполнение программы включает в себя три этапа: компиляция, компоновка и выполнение. Загрузочную программу можно записать на жесткий диск компьютера и использовать многократно для решения задачи, при этом трансляция программы уже не требуется.
Интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Интерпретатор в последовательности выполнения алгоритма считывает очередной оператор программы, переводит его в команды и тут же выполняет эти команды, после чего переходит к переводу и выполнению следующего оператора. При этом результаты предыдущих переводов в оперативной памяти не сохраняются, т.е. при повторном выполнении одной и той же команды она снова будет транслировать.
При интерпретации, поскольку трансляция и выполнение совмещены, обработка программы на компьютере проходит в один этап. Однако откомпилированная программа выполняется быстрее, чем интерпретируемая.
Интерпретаторы возможностью создания загрузочных программ не обладают. В режиме интерпретации удобно отлаживать программу, а рабочие расчеты лучше осуществлять в режиме компиляции.

















Процессор – это основное устройство ЭВМ, выполняющее логические и арифметические операции, и осуществляющее управление всеми компонентами ЭВМ. Процессор представляет собой миниатюрную тонкую кремниевую пластинку прямоугольной формы, на которой размещается огромное количество транзисторов, реализующих все функции, выполняемые процессором. Кремневая пластинка – очень хрупкая, а так как ее любое повреждение приведет к выходу из строя процессора, то она помещается в пластиковый или керамический корпус.
Содержание.1. Введение
2. Ядро процессора
2.1. Принцип работы ядра процессора
2.2. Способы повышения производительности ядра процессора
2.2.1. Конвейеризация
2.2.2. Суперскалярность
2.2.3. Параллельная обработка данных
2.2.4. Технология Hyper-threading
2.2.5. Технология Turbo Boost.
2.2.6. Эффективность выполнения команд.
2.3 Способы снижения энергопотребления ядра процессора
3. КЭШ-память
Современный процессор – это сложное и высокотехнологическое устройство, включающее в себя все самые последние достижения в области вычислительной техники и сопутствующих областей науки.
Большинство современных процессоров состоит из:
одного или нескольких ядер, осуществляющих выполнение всех инструкций;
нескольких уровней КЭШ-памяти (обычно, 2 или три уровня), ускоряющих взаимодействие процессора с ОЗУ;
контроллера системной шины (DMI, QPI, HT и т.д.);
И характеризуется следующими параметрами:
ПЗУ, содержащего микрокод;
Блок выборки инструкций осуществляет считывание инструкций по адресу, указанному в счетчике команд. Обычно, за такт он считывает несколько инструкций. Количество считываемых инструкций обусловлено количеством блоков декодирования, так как необходимо на каждом такте работы максимально загрузить блоки декодирования. Для того чтобы блок выборки инструкций работал оптимально, в ядре процессора имеется предсказатель переходов.
Предсказатель переходов пытается определить, какая последовательность команд будет выполняться после совершения перехода. Это необходимо, чтобы после условного перехода максимально нагрузить конвейер ядра процессора.
Блоки декодирования. как понятно из названия, – это блоки, которые занимаются декодированием инструкций, т.е. определяют, что надо сделать процессору, и какие дополнительные данные нужны для выполнения инструкции. Задача эта для большинства современных коммерческих процессоров, построенных на базе концепции CISC, – очень сложная. Дело в том, что длина инструкций и количество операндов – нефиксированные, и это сильно усложняет жизнь разработчикам процессоров и делает процесс декодирования нетривиальной задачей.
Часто отдельные сложные команды приходится заменять микрокодом – серией простых инструкций, в совокупности выполняющих то же действие, что и одна сложная инструкция. Набор микрокода прошит в ПЗУ, встроенном в процессоре. К тому же микрокод упрощает разработку процессора, так как отпадает надобность в создании сложноустроенных блоков ядра для выполнения отдельных команд, да и исправить микрокод гораздо проще, чем устранить ошибку в функционировании блока.
В современных процессорах, обычно, бывает 2-4 блока декодирования инструкций, например, в процессорах Intel Core 2 каждое ядро содержит по два таких блока.
Блоки выборки данных осуществляют выборку данных из КЭШ-памяти или ОЗУ, необходимых для выполнения текущих инструкций. Обычно, каждое процессорное ядро содержит несколько блоков выборки данных. Например, в процессорах Intel Core используется по два блока выборки данных для каждого ядра.
Управляющий блок на основании декодированных инструкций управляет работой блоков выполнения инструкций, распределяет нагрузку между ними, обеспечивает своевременное и верное выполнение инструкций. Это один из наиболее важных блоков ядра процессора.
Блоки выполнения инструкций включают в себя несколько разнотипных блоков:
ALU – арифметическое логическое устройство;
FPU – устройство по выполнению операций с плавающей точкой;
Блоки для обработки расширения наборов инструкций. Дополнительные инструкции используются для ускорения обработки потоков данных, шифрования и дешифрования, кодирования видео и так далее. Для этого в ядро процессора вводят дополнительные регистры и наборы логики. На данный момент наиболее популярными расширениями наборов инструкция являются:
MMX (Multimedia Extensions) – набор инструкций, разработанный компанией Intel, для ускорения кодирования и декодирования потоковых аудио и видео-данных;
SSE (Streaming SIMD Extensions) – набор инструкций, разработанный компанией Intel, для выполнения одной и той же последовательности операций над множеством данных с распараллеливанием вычислительного процесса. Наборы команд постоянно совершенствуются, и на данный момент имеются ревизии: SSE, SSE2, SSE3, SSSE3, SSE4;
ATA (Application Targeted Accelerator) – набор инструкций, разработанный компанией Intel, для ускорения работы специализированного программного обеспечения и снижения энергопотребления при работе с такими программами. Эти инструкции могут использоваться, например, при расчете контрольных сумм или поиска данных;
3DNow – набор инструкций, разработанный компанией AMD, для расширения возможностей набора инструкций MMX;
AES (Advanced Encryption Standard) – набор инструкций, разработанный компанией Intel, для ускорения работы приложений, использующих шифрование данных по одноименному алгоритму.
Блок сохранения результатов обеспечивает запись результата выполнения инструкции в ОЗУ по адресу, указанному в обрабатываемой инструкции.
Блок работы с прерываниями. Работа с прерываниями – одна из важнейших задач процессора, позволяющая ему своевременно реагировать на события, прерывать ход работы программы и выполнять требуемые от него действия. Благодаря наличию прерываний, процессор способен к псевдопараллельной работе, т.е. к, так называемой, многозадачности.
Обработка прерываний происходит следующим образом. Процессор перед началом каждого цикла работы проверяет наличие запроса на прерывание. Если есть прерывание для обработки, процессор сохраняет в стек адрес инструкции, которую он должен был выполнить, и данные, полученные после выполнения последней инструкции, и переходит к выполнению функции обработки прерывания.
После окончания выполнения функции обработки прерывания, из стека считываются сохраненные в него данные, и процессор возобновляет выполнение восстановленной задачи.
Регистры – сверхбыстрая оперативная память (доступ к регистрам в несколько раз быстрее доступа к КЭШ-памяти) небольшого объема (несколько сотен байт), входящая в состав процессора, для временного хранения промежуточных результатов выполнения инструкций. Регистры процессора делятся на два типа: регистры общего назначения и специальные регистры.
Регистры общего назначения используются при выполнении арифметических и логических операций, или специфических операций дополнительных наборов инструкций (MMX, SSE и т.д.).
Регистры специального назначения содержат системные данные, необходимые для работы процессора. К таким регистрам относятся, например, регистры управления, регистры системных адресов, регистры отладки и т.д. Доступ к этим регистрам жестко регламентирован.
Счетчик команд – регистр, содержащий адрес команды, которую процессор начнет выполнять на следующем такте работы.
2.1 Принцип работы ядра процессора.Принцип работы ядра процессора основан на цикле, описанном еще Джоном фон Нейманом в 1946 году. В упрощенном виде этапы цикла работы ядра процессора можно представить следующим образом:
1. Блок выборки инструкций проверяет наличие прерываний. Если прерывание есть, то данные регистров и счетчика команд заносятся в стек, а в счетчик команд заносится адрес команды обработчика прерываний. По окончанию работы функции обработки прерываний, данные из стека будут восстановлены;
2. Блок выборки инструкций из счетчика команд считывает адрес команды, предназначенной для выполнения. По этому адресу из КЭШ-памяти или ОЗУ считывается команда. Полученные данные передаются в блок декодирования;
3. Блок декодирования команд расшифровывает команду, при необходимости используя для интерпретации команды записанный в ПЗУ микрокод. Если это команда перехода, то в счетчик команд записывается адрес перехода и управление передается в блок выборки инструкций (пункт 1), иначе счетчик команд увеличивается на размер команды (для процессора с длинной команды 32 бита – на 4) и передает управление в блок выборки данных;
4. Блок выборки данных считывает из КЭШ-памяти или ОЗУ требуемые для выполнения команды данные и передает управление планировщику;
5. Управляющий блок определяет, какому блоку выполнения инструкций обработать текущую задачу, и передает управление этому блоку;
6. Блоки выполнения инструкций выполняют требуемые командой действия и передают управление блоку сохранения результатов;
7. При необходимости сохранения результатов в ОЗУ, блок сохранения результатов выполняет требуемые для этого действия и передает управление блоку выборки инструкций (пункт 1).
Описанный выше цикл называется процессом (именно поэтому процессор называется процессором). Последовательность выполняемых команд называется программой.
Скорость перехода от одного этапа цикла к другому определяется тактовой частотой процессора, а время работы каждого этапа цикла и время, затрачиваемое на полное выполнение одной инструкции, определяется устройством ядра процессора.
2.2. Способы повышения производительности ядра процессора.Увеличение производительности ядра процессора, за счет поднятия тактовый частоты, имеет жесткое ограничение. Увеличение тактовой частоты влечет за собой повышение температуры процессора, энергопотребления и снижение стабильности его работы и срока службы.
Поэтому разработчики процессоров применяют различные архитектурные решения, позволяющие увеличить производительность процессоров без увеличения тактовой частоты.
Рассмотрим основные способы повышения производительности процессоров.
2.2.1. Конвейеризация.Каждая инструкция, выполняемая процессором, последовательно проходит все блоки ядра, в каждом из которых совершается своя часть действий, необходимых для выполнения инструкции. Если приступать к обработке новой инструкции только после завершения работы над первой инструкцией, то большая часть блоков ядра процессора в каждый момент времени будет простаивать, а, следовательно, возможности процессора будут использоваться не полностью.
Рассмотрим пример, в котором процессор будет выполнять программу, состоящую из пяти инструкций (К1–К5), без использования принципа конвейеризации. Для упрощения примера примем, что каждый блок ядра процессора выполняет инструкцию за 1 такт.
Та же программа была выполнена за 9 тактов, что почти 2.8 раза быстрее, чем при работе без конвейера. Как видно из таблицы максимальная загрузка процессора была получена на 5 такте. В этот момент использовались все блоки ядра процессора. А с первого по четвертый такт, включительно, происходило наполнение конвейера.
Так как процессор выполняет команды непрерывно, то, в идеале, он мог бы быть занят на 100%, при этом, чем длиннее был бы конвейер, тем больший выигрыш в производительности был бы получен. Но на практике это не так.
Во-первых, реальный поток команд, обрабатываемый процессором – непоследовательный. В нем часто встречаются переходы. При этом пока команда условного перехода не будет обработана полностью, конвейер не сможет начать выполнение новой команды, так как не знает, по какому адресу она находится.
После условного перехода конвейер приходится наполнять заново. И чем длиннее конвейер, тем дольше это происходит. В результате, прирост производительности от введения конвейера снижается.
Для уменьшения влияния условных переходов на работу конвейера, в ядро процессора вводятся блоки предсказания условных переходов. Основная задача этих блоков – определить, когда будет совершен условный переход и какие команды будут выполнены после совершения условного перехода.
Если условный переход удалось предсказать, то выполнение инструкций по новому адресу начинается раньше, чем будет закончена обработка команды условного перехода. В результате, наполнение конвейера не пострадает.
По статистике, точность блоков предсказания условных переходов в современных процессорах превышает 90%, что позволяет делать достаточно длинные, но при этом хорошо наполняемые конвейеры.
Во-вторых, часто обрабатываемые инструкции – взаимосвязаны, то есть одна из инструкций требует в качестве исходных данных результата выполнения другой инструкции.
В этом случае она может быть выполнена только после полного завершения обработки первой инструкции. Однако современные процессоры могут анализировать код на несколько инструкций вперед и, например, параллельно с первой инструкцией обработать третью инструкцию, которая никак не зависит от первых двух.
В большинстве современных процессорах задача анализа взаимосвязи инструкций и составления порядка их обработки ложится на плечи процессора, что неминуемо ведет к снижению его быстродействия и увеличению стоимости.
Однако все большую популярность получает статическое планирование, когда порядок выполнения программы процессором определяется на этапе компиляции программы. В этом случае инструкции, которые можно выполнить параллельно, объединяются компилятором в одну длинную команду, в которой все инструкции заведомо параллельны. Процессоры, работающие с такими инструкциями, построены на базе архитектура VLIW (Very long instruction word).
2.2.2. Суперскалярность.Суперскалярность – архитектура вычислительного ядра, при которой наиболее нагруженные блоки могут входить в нескольких экземплярах. Скажем, в ядре процессора блок выборки инструкций может нагружать сразу несколько блоков декодирования.
В этом случае блоки, выполняющие более сложные действия и работающие дольше, за счет параллельной обработки сразу нескольких инструкций не будут задерживать весь конвейер.
Однако параллельное выполнение инструкций возможно, только если эти инструкции – независимые.
Структурная схема ядра конвейера гипотетического процессора, построенного с использованием принципа суперскалярности, приведена на рисунке 1. На этом рисунке в каждом ядре процессора работает несколько блоков декодирования, несколько блоков выборки данных и несколько блоков выполнения инструкций.
2.2.3. Параллельная обработка данных.Бесконечно повышать производительность процессоров, за счет увеличения тактовой частоты, невозможно. Увеличение тактовой частоты влечет за собой увеличение тепловыделения, уменьшение срока службы и надежности работы процессоров, да и задержки от обращения к памяти сильно снижают эффект от увеличения тактовой частоты. Действительно, сейчас практически не встретишь процессоры с тактовой частотой выше 3.8 ГГц.
Связанные с увеличением тактовой частоты проблемы заставляют разработчиков искать иные пути повышения производительности процессоров. Один из наиболее популярных способов – параллельные вычисления.
Подавляющее большинство современных процессоров имеют два и более ядра. Топовые модели могут содержать и 8, и даже 12 ядер, причем с поддержкой технологии hyper-threading. Преимущества от ввода дополнительных ядер вполне понятны, мы практически получаем несколько процессоров, способных независимо решать каждый свои задачи, при этом, естественно, возрастает производительность. Однако прирост производительности далеко не всегда оправдывает ожидания.
Во-первых, далеко не все программы поддерживают распределение вычислений на несколько ядер. Естественно, можно программы разделять между ядрами, чтобы на каждом ядре работал свой набор независимых программ. Например, на одном ядре работает операционная система с набором служебных программ, на другом пользовательские программы и так далее.
Но это дает выигрыш в производительности до тех пор, пока не появляется программа, требующая ресурсов больше, чем может дать одно ядро. Хорошо, если она поддерживает распределение нагрузки между несколькими ядрами. Но на данный момент общедоступных программ, способных распределить нагрузку между 12 ядрам, да еще в режиме Hyper-Threading, можно «сосчитать на пальцах одной руки». Я, конечно, утрирую, существуют программы, оптимизированные для многопоточных вычислений, но большинству простых пользователей они не нужны. А вот наиболее популярные программы, а тем более игры, пока что «плохо» адаптируются к многоядерным процессорам, особенно, если количество ядер больше четырех.

Статья создана: 2010-09-08. обновлена: 2015-12-20
Архитектура фон НейманаВ 1945 года в отчете по ЭВМ EDVAC Дж. фон Нейман сформулировал основные принципы построения ЭВМ. Вычислительная система, согласно фон Нейману, должна включать следующие компоненты: центральное арифметическое устройство; центральное устройство управления; главную память; устройства ввода-вывода.
По прошествии более полувека большинство компьютеров так и имеют «фон неймановскую архитектуру».
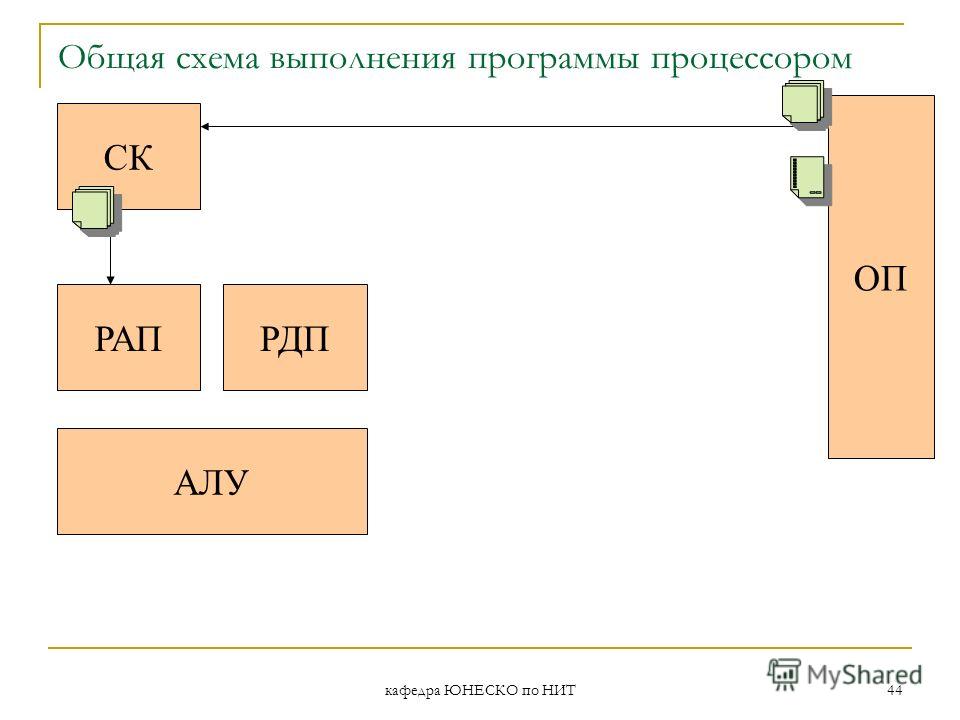
Процессором является определенная функционально полная совокупность устройств, которая регулирует, управляет и контролирует соответствующий рабочий процесс. В персональных компьютерах таким рабочим процессом является процесс обработки данных, а сама совокупность устройств называется процессором.
В состав микропроцессора входят несколько типовых компонентов. Подробнее читайте далее.
Устройство управленияУстройство управления (УУ) формирует и подает во все блоки машины в нужные моменты времени определенные сигналы управления (управляющие импульсы), обусловленные спецификой выполняемой операции и результатами предыдущих операций; формирует адреса слов (ячеек) памяти, используемых выполняемой операцией, и передает эти адреса в соответствующие блоки компьютера; опорную последовательность импульсов устройство управления получает от генератора тактовых импульсов.
Арифметико-логическое устройствоАрифметико-логическое устройство (АЛУ) предназначено для выполнения арифметических (обычно это короткие операции - с фиксированной точкой, ФТ) и логических операций над числовой и символьной информацией.
Микропроцессорная памятьМикропроцессорная память (МПП, или кэш-память 1-го уровня - L1 cache) предназначена для кратковременного хранения, записи и выдачи информации, непосредственно используемой в ближайшие такты работы машины.
Интерфейсная система микропроцессораИнтерфейсная система микропроцессора предназначена для сопряжения и связи с другими устройствами ПК.
Генератор тактовых импульсов (internal clock)Генератор тактовых импульсов (internal clock) генерирует последовательность электрических импульсов, частота которых определяет тактовую частоту микропроцессора - электронные часы реального времени, обеспечивающие при необходимости автоматический съем текущего момента времени.
Перечислим далее основные понятия, связанные с работой процессора.
Команда, инструкция (instruction)Команда, инструкция (instruction) - описание операции, которую нужно выполнить. Каждая команда начинается с кода операции (КОП), содержит необходимые адреса, характеризуется форматом, который определяет структуру команды.
Команды подразделяются на арифметические, логические, ввода/вывода, передачи данных. Каждая команда выполняется в компьютере за один либо несколько тактов.
Цикл процессораЦикл процессора - период времени, за который осуществляется выполнение команды исходной программы в машинном виде; состоит из нескольких тактов.
Такт работы процессорТакт работы процессора - промежуток времени между соседними импульсами (tick of the internal clock) генератора тактовых импульсов. частота которых есть тактовая частота процессора. Такт процессора (такт синхронизации) - квант времени, в течение которого осуществляется элементарная операция - выборка, сравнение, пересылка данных. Выполнение короткой команды - арифметика с ФТ, логические операции, обычно занимает пять тактов:
Процедура, соответствующая такту, реализуется определенной логической цепью (схемой) процессора, обычно именуемой микропрограммой .
Регистры - устройства, предназначенные для временного хранения данных ограниченного размера. Важной характеристикой регистра является высокая скорость приема и выдачи данных. Регистр, обладающий способностью перемещать содержимое своих разрядов, называют сдвиговым. Некоторые регистры служат счетчиками. Счетчик является устройством, которое на своих выходах выдает (в двоичной форме) сумму числа импульсов, подаваемых на его единственный вход. Максимальное число импульсов, которое счетчик может подсчитать, называется его емкостью.
Регистры общего назначения (РОН, General Purpose Registers) - общее название для регистров, которые временно содержат данные, передаваемые или принимаемые из памяти.
Регистр команды (РК, Instruction Register IR) служит для размещения текущей команды, которая находится в нем в течение текущего цикла процессора.
Регистр - (РАК) счетчик (СчАК) адреса команды (program counter, PC) - регистр, содержащий адрес текущей команды.
Сумматор - регистр, осуществляющий операции сложения (логического и арифметического двоичного) чисел или битовых строк, представленных в прямом или обратном коде. (Иногда РЧ и РР включают в состав сумматора).
Существуют и другие регистры, например, регистр состояния - Status Register (SR). Типичным содержанием SR является информация о результатах завершения команды (ноль, переполнение, деление на ноль, перенос и прочее). УУ использует информацию из SR для исполнения условных переходов (например, «в случае переполнения перейти по адресу 4170»).
Цикл командыЦикл выполнения короткой команды может выглядеть следующим образом.
1. В соответствии с содержимым СчАК (адрес очередной команды) УУ извлекает из ОП очередную команду и помещает ее в РК. Некоторые команды УУ обрабатывает самостоятельно, без привлечения АЛУ (например, по команде «перейти по адресу 2478» величина 2478 сразу заносится в СчАК, и процессор переходит к выполнению следующей команды).
Типичная команда содержит:
2. Осуществляется расшифровка (декодирование) команды.
3. Адреса A1, А2 и прочие, помещаются в регистры адреса.
4. Если в команде указаны ИР или БР, то их содержимое используется для модификации РА - фактически выбираются числа или команды, смещенные в ту или иную сторону по отношению к адресу, указанному в команде.
5. По значениям РА осуществляется чтение чисел (строк) и помещение их в РЧ.
6. Выполнение операции и помещение результата в PP.
7. Запись результата по одному из адресов (если необходимо).
8. Увеличение содержимого СчАК на единицу (переход к следующей команде).
Очевидно, что за счет увеличения числа регистров возможно распараллеливание. перекрытие операций. Например, при считывании команды СчАК можно автоматически увеличить на 1, подготовив выборку следующей команды. После расшифровки текущей команды РК освобождается и в него может быть прочитана следующая команда. При выполнении операции возможна расшифровка следующей команды и так далее Все это является предпосылкой построения так называемых конвейерных структур (pipeline). Однако все это хорошо только при последовательном (естественном) порядке выполнения команд. Появление переходов (особенно по не определенному заранее условию) нарушает эту картину. Поэтому современные процессоры пытаются предсказывать переходы в программе (branch prediction).
Системы команд и соответствующие классы процессоровОсновные команды ЭВМ классифицируются вкратце следующим образом: по функциям (выполняемым операциям), направлению приема-передачи информации, адресности.
Классы команд1. Команды обработки данных, в том числе (01 - первый операнд, 02 - второй):
1.1. Короткие операции (один такт).
- логическое сложение (для каждого бита 01 и 02 осуществляется операция ИЛИ;
- логическое умножение (для каждого бита О! и 02 осуществляется операция И;
- инверсия (в O1 все единицы заменяются на нули, и наоборот);
- сравнение логическое (если O1=02, то некий регистр устанавливается в 1, иначе - в 0).
- сложение или вычитание операндов;
- сравнение арифметическое (если O1 > O2, или O1=O2, или O1 < O2, то некий регистр устанавливается в 1, иначе - в 0).
1.2. Длинные операции (несколько тактов):
- сложение/вычитание с фиксированной точкой;
- умножение/деление с фиксированной точкой.
2. Операции управления:
- безусловный переход (ветвление, branch);
- условный переход (по условию, результатам вычислений (conditional branch)).
3. Операции обращения к внешним устройствам (требование на запись или считывание информации).
Естественно, могут существовать и другие операции - десятичная арифметика. обработка символьной информации, работа с числами половинной (полуслово, например 16 бит) или двойной (двойное слово, например 64 бит) длины.
Кроме того, команды различаются по типу выборки и пересылок данных: регистр-регистр; память-регистр (регистр-память); память-память.
Далее, известны одно-, двух- и трехадресные машины (системы команд). Очевидна связь таких параметров ЦУ, как длина адресного пространства, адресность, разрядность. Увеличение разрядности позволяет увеличить адресность команды и длину адреса (то есть объем памяти, доступной данной команде). Увеличение адресности, в свою очередь, приводит к повышению быстродействия обработки (за счет снижения числа требуемых команд).
В трехадресной машине, например, сложение двух чисел требует одной команды (извлечь число по А1, число по А2, сложить и записать результат по A3). В двухадресной необходимы две команды (первая - извлечь число по А1 и поместить в РЧ (или сумматор), вторая - извлечь число по А1, сложить с содержимым РЧ и результат записать по А2). Легко видеть, что одноадресная машина потребует три команды. Поэтому неудивительно, что основная тенденция в развитии ЦУ ЭВМ состоит в увеличении разрядности.
Наибольшее применение нашли двухадресные системы команд.
Классы процессоровВ зависимости от набора и порядка выполнения команд процессоры подразделяются на два основных класса, отражающих также последовательность развития ЭВМ. Ранее других появились процессоры CISC. Затем с целью повышения быстродействия процессоров были разработаны процессоры RISC, которые характеризуются сокращенным набором быстровыполняемых команд. Ряд редко встречающихся команд процессора CISC выполняется последовательностями команд процессора RISC.
CISC (complex instruction set computer)CISC (complex instruction set computer) есть традиционная архитектура, в которой центральный процессор использует микропрограммы для выполнения исчерпывающего набора команд. В течение долгих лет производители компьютеров разрабатывали и воплощали в изделиях все более сложные и полные системы команд. Однако анализ работы процессоров показал, что примерно 80 % времени выполняется лишь 20 % большого набора команд. Поэтому была поставлена задача оптимизации выполнения небольшого по числу, но часто используемых команд.
RISC (Redused Instruction Set Computer)RISC (Redused Instruction Set Computer) - процессор, функционирующий с сокращенным набором команд. Так, в процессоре CISC для выполнения одной команды необходимо в большинстве случаев 10 и более тактов. Что же касается процессоров RISC, то они близки к тому, чтобы выполнять по одной команде в каждом такте. Первый процессор RISC был создан корпорацией IBM в 1979 году и имел шифр IBM 801. В настоящее время процессоры RISC получили широкое распространение. Современные процессоры RISC имеют следующие характеристики:
Новый подход к архитектуре процессора значительно сократил площадь, требуемую для него на чипе. Это позволило резко увеличить число регистров. В современном процессоре RISC уже используется более 100 регистров. В результате процессор на 20-30 % реже обращается к оперативной памяти, что также повысило скорость обработки данных.
Начиная с процессора Pentium, корпорация Intel начала внедрять элементы RISC-технологий в свои изделия.
Кроме того, известны процессоры MISC (работающие с минимальным набором длинных команд) и VLIW (с системой команд сверхбольшой разрядности).
Процессор VL1WПроцессор VL1W - процессор, работающий с системой команд сверхбольшой разрядности.
Идея технологии VLIW (Very large instruction word) заключается в том, что создается специальный компилятор планирования, который перед выполнением прикладной программы проводит ее анализ и по множеству ветвей последовательности операций определяет группу команд, которые могут выполняться параллельно. Каждая такая группа образует одну сверхдлинную команду. Это позволяет решать две важные задачи: во-первых, в течение одного такта выполнять группу коротких («обычных») команд, во-вторых, упростить структуру процессора. Этим технология VLIW отличается от суперскалярности. В последнем случае отбор групп одновременно выполняемых команд происходит непосредственно в ходе выполнения прикладной программы (а не заранее), что усложняет структуру процессора и замедляет его скорость.
Процессор MISCПроцессор MISC - MISC processor, - работающий с минимальным набором длинных команд.
Увеличение разрядности процессоров привело к идее укладки нескольких команд в одно слово (связку, bound) размером 128 бит. Оперируя с одним словом, процессор получил возможность обрабатывать сразу несколько команд. Это позволило использовать возросшую производительность компьютера и его возможность обрабатывать одновременно несколько потоков данных.
Технологии повышения производительности процессоров Конвейерная обработка команд (pipelining). СуперскаляризацияРассмотрим процесс выполнения процессором команды для коротких (с ФТ или логические) операций. Как об этом говорилось ранее, обработка команды, или цикл процессора, может быть разделена на несколько основных этапов, которые можно назвать микрокомандами, которых известно пять основных типов.
Каждая операция требует для своего выполнения времени, равного такту генератора процессора. Отметим, что к длинным операциям (ПТ) это не имеет отношения - там другая арифметика. Очевидно, что при тактовой частоте в 100 МГц быстродействие составит 20 млн операций в секунду.
Все этапы команды задействуются только 1 раз и всегда в одном и том же порядке: одна за другой. Это, в частности, означает, что если первая микрокоманда выполнила свою работу и передала результаты второй, то для выполнения текущей команды она больше не понадобится и, следовательно, может приступить к выполнению следующей команды.
Конвейеризация осуществляет многопоточную параллельную обработку команд, так что в каждый момент одна из команд считы-вается, другая декодируется и так далее, и всего в обработке одновременно находится пять команд. Таким образом, на выходе конвейера на каждом такте процессора появляется результат обработки одной команды (одна команда в один такт). Первая инструкция может считаться выполненной, когда завершат работу все пять микрокоманд.
Такая технология обработки команд носит название конвейерной (pipeline) обработки. Каждая часть устройства называется ступенью конвейера, а общее число ступеней - длиной линии конвейера.
С ростом числа линий конвейера и увеличением числа ступеней на линии увеличивается пропускная способность процессора при неизменной тактовой частоте. Процессоры с несколькими линиями конвейера получили название суперскалярных. Pentium - первый суперскалярный процессор Intel. Здесь две линии, что позволяет ему при одинаковых частотах быть вдвое производительней i80486, выполняя сразу две команды за такт.
Таблица характеристик конвейеров процессоров Intel
Блоки операций с плавающей запятойНачиная с 80486 восемь регистров для ПЗ (именуемых ST(0) - ST (7)) встраивают в центральный процессор. Каждый регистр имеет ширину 80 бит и хранит числа в формате стандарта ПЗ расширенной точности (IEEE floating-point standard).
Эти регистры доступны в стековом порядке. Имена (номера) регистров устанавливаются относительно вершины стека (ST (0) - вершина стека, ST(1) - следующий регистр ниже вершины стека, ST (2) - второй после вершины стека и так далее). Вводимые данные таким образом всегда сдвигаются «вниз» от вершины стека, а текущая операция совершается с содержимым вершины стека.
SlMD - процессы (команды)Г. Флинном в 1966 году была предложена классификация ЭВМ и вычислительных систем (в основном - суперкомпьютеров), основанная на совместном рассмотрении потоков команд и данных. В процессорах таких известных производителей как Intel и AMD все более полно используются некоторые из этих архитектурных наработок.
Таблица классификации ФлиннаSISD - Single Instruction stream/Single Data stream (Одиночный поток Команд и Одиночный поток Данных - ОКОД)
MISD - Multiple Instruction stream/ Single Data stream (Множественный поток Команд и Одиночный поток Данных - МКОД)
SIMD - Single Instruction stream/Multiple Data stream (Одиночный поток Команд и Множественный поток Данных - ОКМД)
MIMD - Multiple Instruction stream/Multiple Data stream (Множественный поток Команд и Множественный поток Данных -МКМД)
Например, в общем случае архитектура SIMD (ОКМД) предполагает создание структур векторной или матричной обработки. Под эту схему хорошо подходят задачи обработки матриц или векторов (массивов), задачи решения систем линейных и нелинейных, алгебраических и дифференциальных уравнений, задачи теории поля и другое
В микропроцессорах массового выпуска при обработке мультимедийных данных также целесообразно применять подобные решения.
Динамическое исполнение (dynamic execution technology)Динамическое исполнение - технология обработки данных процессором, обеспечивающая более эффективную работу процессора за счет манипулирования данными, а не просто линейного исполнения списка инструкций.
Предсказание ветвленийС большой точностью (более 90 %) процессор предсказывает, в какой области памяти можно найти следующие инструкции. Это оказывается возможным, поскольку в процессе исполнения инструкции процессор просматривает программу на несколько шагов вперед.
Внеочередное выполнение (выполнение вне естественного порядка - out-of-order executionПроцессор анализирует поток команд и составляет график исполнения инструкций в оптимальной последовательности независимо от порядка их следования в тексте программы, просматривая декодированные инструкции и определяя, готовы ли они к непосредственному исполнению или зависят от результата других инструкций. Далее процессор определяет оптимальную последовательность выполнения и исполняет инструкции наиболее эффективным образом.
Переименование (ротация) регистров (register renameЧтобы избежать пересылок данных между регистрами в соответствующей команде изменяется адрес регистра, содержащего данные, участвующие в следующей операции. Поэтому вместо пересылки данных в регистр-источник осуществляется трактовка регистра с данными как источника.
Выполнение по предположению (спекулятивное - speculativeПроцессор выполняет инструкции (до пяти инструкций одновременно) по мере их поступления в оптимизированной последовательности (спекулятивно). Поскольку выполнение инструкций происходит на основе предсказания ветвлений, результаты сохраняются как предположительные («спекулятивные»). На конечном этапе порядок инструкций восстанавливается.
Существуют следующие варианты спекулятивного выполнения:
Эти возможности осуществляются комбинированно - при компиляции и выполнении программы.
ПредикацииОбычный компилятор транслирует оператор ветвления (например, if-then-else) в блоки машинного кода, расположенные последовательно в потоке. Обычный процессор в зависимости от исхода условия исполняет один из этих базовых блоков, пропуская все другие. Более развитые процессоры пытаются прогнозировать исход операции и предварительно выполняют предсказанный блок. При этом в случае ошибки много тактов тратится впустую. Сами блоки зачастую весьма малы - две или три команды, - а ветвления встречаются в коде в среднем каждые шесть манд. Такая структура кода делает крайне сложным его параллельное выполнение.
При использовании предикации компилятор, обнаружив оператор ветвления в исходной программе, анализирует все возможные ветви (блоки) и помечает их метками или предикатами (predicate). После этого он определяет, какие из них могут быть выполнены параллельно (из соседних, независимых ветвей).
В процессе выполнения программы центральный процессор выбирает команды, которые взаимно независимы и распределяет их на параллельную обработку. Если центральный процессор обнаруживает оператор ветвления, он не пытается предсказать переход, а начинает выполнять все возможные ветви программы.
Таким образом, могут быть обработаны все ветви программы, но без записи полученного результата. В определенный момент процессор наконец «узнает» о реальном исходе условного оператора, записывает в память результат «правильной ветви» и отменяет остальные результаты.
В то же время, если компилятор не «отметил» ветвление, процессор действует как обычно - пытается предсказать путь ветвления и так далее Испытания показали, что описанная технология позволяет устранить более половины ветвлений в типичной программе, и, следовательно, уменьшить более чем в 2 раза число возможных ошибок в предсказаниях.
Опережающее чтенияОпережающее чтение (предварительная загрузка данных, чтение по предположению) разделяет загрузку данных в регистры и их реальное использование, избегая ситуации, когда процессору приходится ожидать прихода данных, чтобы начать их обработку.
Прежде всего, компилятор анализирует программу, определяя команды, которые требуют приема данных из оперативной памяти. Там, где это возможно, он вставляет команды опережающего чтения и парную команду контроля опережающего чтения (speculative check). В то же время компилятор переставляет команды таким образом, чтобы центральный процессор мог их обрабатывать параллельно.
В процессе работы центрального процессора встречает команду опережающего чтения и пытается выбрать данные из памяти. Может оказаться, что они еще не готовы (результат работы блока команд, который еще не выполнился). Обычный процессор в этой ситуации выдает сообщение об ошибке, однако система откладывает «сигнал тревоги» до момента прихода процесса в точку «команда проверки опережающего чтения». Если к этому моменту все предшествующие подпроцессы завершены и данные считаны, то обработка продолжается, в противном случае вырабатывается сигнал прерывания.
Многократное декодирование командВ то время как традиционный процессор линейно переводит команды в тактовые микрокоманды и последовательно их выполняет, центральный процессор с многократным декодированием сначала преобразует коды исходных команд программы в некоторые вторичные псевдокоды (предварительное декодирование, или предекодирование), которые затем более эффективно исполняет ядро процессора. Эти преобразования могут содержать несколько этапов. В качестве примеров рассмотрим 2-3-ступенчатые декодеры.
Декодирование команд CISC/RISC в VLIW. Эти технологии использованы в мобильных процессорах Crusoe (фирма Transmeta) и некоторых центральных процессорах Intel - архитектуры IA-64 и EPIC (Explicitly Parallel Instruction Computing - вычисления с явной параллельностью инструкций).
В частности, в Crusoe на входе процессора - программы, подготовленные в системе команд Intel х86, однако внутренняя система команд VLIW не имеет ничего общего с командами х86 и разработана для быстрого выполнения при малой мощности, используя обычную CMOS-технологию. Окружающий уровень программного называют программным обеспечением модификации кодов (Code Morphing software - CMS, или CM), здесь осуществляется динамический перевод команд х86 в команды VLIW.
Аналогичные приемы используются в процессорах Intel Itanium - здесь при компиляции готовятся пакеты (связки, bundles) команд (по 3 команды в 128-битовом пакете). Тем самым, компилятор выполняет в данном случае функции СМ.
Декодирование команд CISC VLIW в RISCУказанные выше достоинства RISC-архитектуры привели к тому, что во многих современных CISC-процессорах используется RISC-ядро, выполняющее обработку данных. При этом поступающие сложные и разноформатные команды предварительно преобразуются в последовательность простых RISC-операций, быстро выполняемых этим процессорным ядром. Таким образом, работают, например, современные модели процессоров Pentium и К7, которые по внешним показателям относятся к CISC-процессорам. Использование RISC-архитектуры является характерной чертой многих современных процессоров.
Макрослияние (macrofusion)В процессорах предыдущих поколений каждая выбранная команда отдельно декодируется и выполняется. Макрослияние позволяет объединять типичные пары последовательных команд (например, сравнение, сопровождающееся условным переходом) в единственную внутреннюю команду-микрооперацию (МкОП, micro-op) в процессе декодирования. В дальнейшем две команды выполняются как одна МкОП, сокращая полный объем работы процессора.
Микрослияние (micro-op fusion)В современных доминирующих процессорах команды х86 (macro-ops) обычно расчленяются на МкОП прежде, чем передаются на конвейер процессора. Микрослияние группирует и соединяет МкОП, уменьшая их число. Исследования показали, что слияние МкОП вкупе с выполнением команд в измененном порядке может уменьшить число МкОП более чем на 10 процентов. Данная технология использована в системах Intel Core, а ранее апробировалась в ПЦ мобильных систем Pentium М.
В процессорах AMD К8 конвейер строится на том, что работа с потоком МкОП происходит тройками инструкций (AMD называет их линиями - line). Конвейер К8 обрабатывает именно линии, а не х86-инструкции или отдельные микрооперации.
Технология Hyper-Threading (НТ)Здесь реализуется разделение времени на аппаратном уровне, Разбивая физический процессор на два логических процессора, каждый из которых использует ресурсы чипа - ядро, кэш-память, шины, исполнительное устройство.
Благодаря НТ многопроцессная операционная система использует один процессор как два и выдает одновременно два потока команд. Смысл технологии заключается в том, что в большинстве случаев исполнительные устройства процессора далеки от полной загруженности. От передачи на выполнение вдвое большего потока команд повышается загрузка исполнительных устройств.
Технологии «невыполнимых битов»Технологии «невыполнимых битов» (No-eXecute bit). Бит «NX» (63-й бит адреса) позволяет операционной системе определить, какие страницы адреса могут содержать исполняемые коды, а какие - нет. Попытка обратиться к NX-адресу как к исполняемой программе вызывает событие «нарушение защиты памяти», подобное попытке обратиться к памяти «только для чтения» или к области размещения ОС. Этим может быть запрещено выполнение программного кода, находящегося в некоторых страницах памяти, таким образом предотвращая вирусные или хакерские атаки. С теоретической точки зрения, здесь осуществляется виртуальное назначение «Гарвардской архитектуры» - разделение памяти для команд и для данных. Обозначение «NX-bit» используется AMD, Intel использует выражение «XD-bit» (eXecute Disable bit).
Дополнительная информация по темеПодробное описание истории и устройство процессоров компании AMD, с графическими схемами и сравнительными характеристиками
Подробное описание истории и устройство процессоров компании Intel, с графическими схемами и сравнительными характеристиками
Подробное описание истории и устройство процессоров компании Cyrix с использованием графических схем
Описание разных производителей процессоров, которые не смогли попасть в лидеры процессорного рынка







