
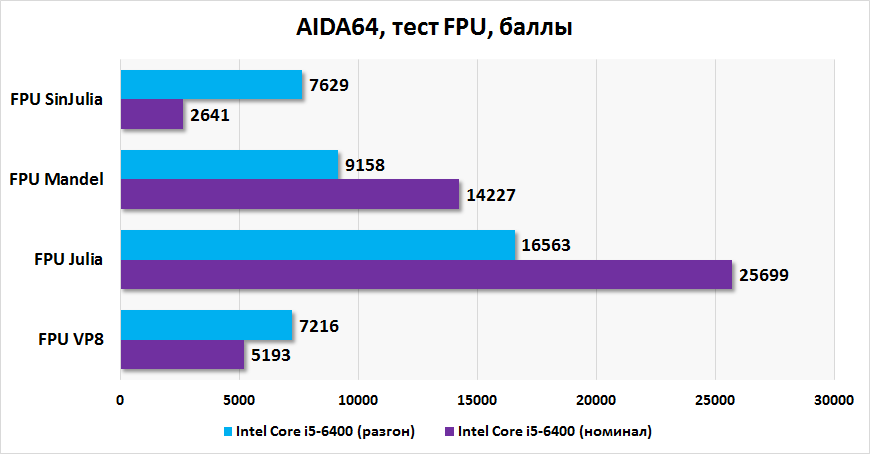
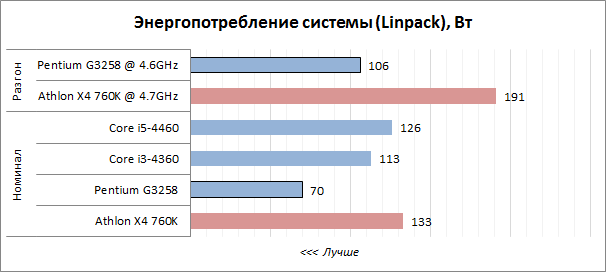
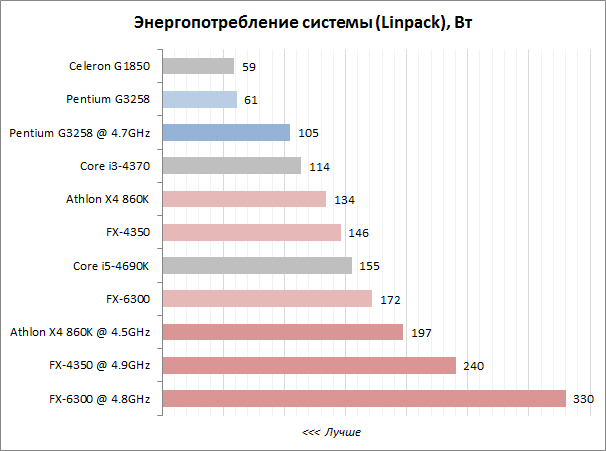

Категория: Инструкции
 можно использовать
можно использовать  , при этом регистр
, при этом регистр  остаётся неизменённым. В случаях, когда значение используется дальше в вычислениях, это повышает производительность, так как избавляет от необходимости сохранять перед вычислением и восстанавливать после вычисления регистр, содержавший , из другого регистра или памяти.
остаётся неизменённым. В случаях, когда значение используется дальше в вычислениях, это повышает производительность, так как избавляет от необходимости сохранять перед вычислением и восстанавливать после вычисления регистр, содержавший , из другого регистра или памяти.Новая схема кодирования инструкций VEX использует VEX префикс. В настоящий момент существуют два VEX префикса, длиной 2 и 3 байта. Для 2-х байтного VEX префикса первый байт равен 0xC5, для 3-х байтного 0xC4. В 64-битном режиме первый байт VEX префикса уникален. В 32-битном режиме возникает конфликт с инструкциями LES и LDS, который разрешается старшим битом второго байта, он имеет значение только в 64-битном режиме, через неподдерживаемые формы инструкций LES и LDS. [4] Длина существующих AVX инструкций, вместе с VEX префиксом, не превышает 11 байт. В следующих версиях ожидается появление более длинных инструкций.
Новые инструкции Смотреть что такое "AVX" в других словарях:Avx — <<
AVX — Sigles d’une seule lettre Sigles de deux lettres > Sigles de trois lettres Sigles de quatre lettres Sigles de cinq lettres Sigles de six lettres Sigles de sept… … Wikipedia en Francais
AVX — A V X Corporation (Business » NYSE Symbols) … Abbreviations dictionary
AVX — Catalina Island Avalon Bay, CA, USA internationale Flughafen Kennung … Acronyms
AVX — Catalina Island Avalon Bay, CA, USA internationale Fughafen Kennung … Acronyms von A bis Z
AVX — abbr. AntiVirus eXpert … Dictionary of abbreviations
Catalina Airport — AVX forwards here. For the Intel SIMD instruction set, see Advanced Vector Extensions.Infobox Airport name = Catalina Airport image width = 200 caption = Douglas DC 3 on take off image2 width = 150 caption2 = Catalina Airport runway diagram IATA … Wikipedia
Surface-mount technology — (SMT) is a method for constructing electronic circuits in which the components (SMC, or Surface Mounted Components) are mounted directly onto the surface of printed circuit boards (PCBs). Electronic devices so made are called surface mount… … Wikipedia
Tecnologia de montaje superficial — Varios dispositivos SMD. La tecnologia de montaje superficial, mas conocida por sus siglas en ingles SMT (Surface Mount Technology) es el metodo de construccion de dispositivos electronicos mas utilizado actualmente. Se usa tanto para componentes … Wikipedia Espanol
Advanced Vector Extensions — (AVX) ist eine Erweiterung des x86 Befehlssatzes fur Mikroprozessoren von Intel und AMD, die von Intel im Marz 2008 vorgeschlagen wurde.[1] Inhaltsverzeichnis 1 Neue Eigenschaften 2 Neue Instruktionen … Deutsch Wikipedia


















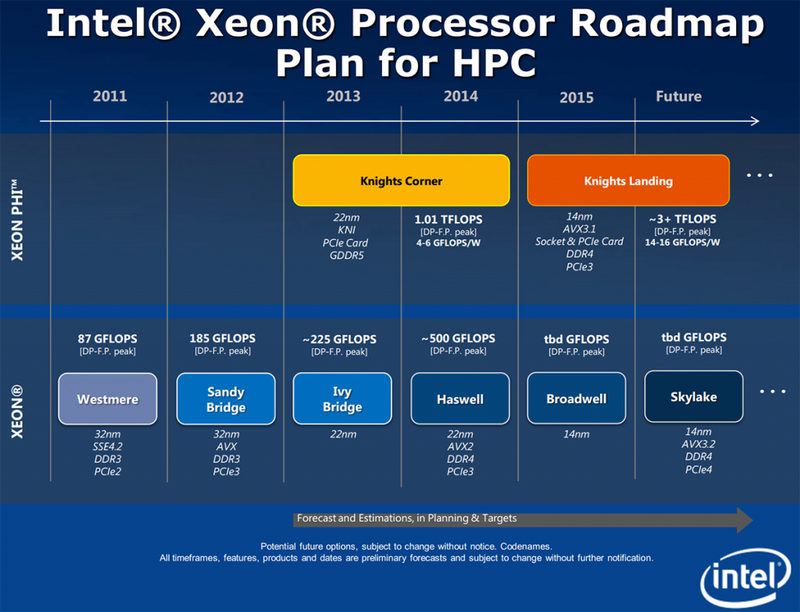
Как сообщают зарубежные источники, будущие настольные процессоры Intel под кодовым названием Skylake не будут поддерживать набор инструкций AVX-512. Это станет уделом только серверных моделей Xeon, которые, впрочем, также применяются и в рабочих станциях. Ранее ожидалось, что поддержка 512-битных инструкций SIMD, известных под общим именем AVX3 станет одной из ключевых особенностей Skylake и поможет ему демонстрировать непревзойдённый уровень производительности в приложениях, которые умеют использовать новые наборы инструкций.
Но, если верить ресурсу Bits & Chips. Intel решила не включать поддержку каких-либо расширений AVX-512 в обычной, «бытовой» версии Skylake, в то время, как будущие поколения Xeon с этой же микроархитектурой такие расширения поддерживать будут. Но даже Xeon не будут обладать поддержкой некоторых 512-битных инструкций, с которыми умеют работать сопроцессоры Intel Xeon Knights Landing. Ранее ожидалось, что процессоры Skylake будут поддерживать набор инструкций AVX 3.2. Для сравнения, Knights Landing поддерживает AVX 3.1. Похоже, лишь процессоры под кодовым именем Cannonlake, которые увидят свет лишь в конце 2016 — начале 2017 года будут поддерживать большинство 512-битных расширений AVX, да и то не все.
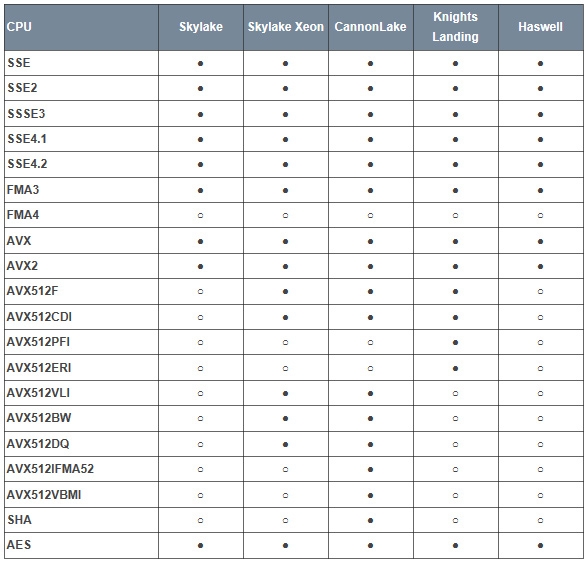
Кроме того, неизвестно, идёт ли речь об обычной, настольной версии Cannonlake или же, как и в случае со Skylake, о Xeon. Что касается пользы от 512-битных инструкций, то они, конечно, будут полезны в сфере высокопроизводительных вычислений, но от их использования может выиграть и обычный пользователь, особенно если речь идёт о требовательных мультимедийных приложениях. Отказ от поддержки 512-битных инструкций «бытовыми» процессорами в итоге приведёт к значительному снижению темпов их внедрения в программное обеспечение. В целом же, без AVX 3.2 Skylake теряет большую часть своей потенциальной привлекательности и практически перестаёт отличаться от Haswell и Broadwell, что не может не печалить. Официальных комментариев со стороны Intel на эту новость пока не поступало.
Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
В треде www.linux.org.ru/forum/talks/12273860 подняли интересный вопрос производительности как раз именно FPU и его продолжений/вариантов. А как вообще возможно понять надо ли это софтине? Вот, например, ставлю я nginx. Надо ему вычисления с плаващей точкой или нет? А если это nginx в виртуалке в qemu-kvm? В этой цепи используются такие вычисления? Может быть есть ресурс, где софт классифицирован по этому признаку?
Спасибо.
ЗЫ. Я хз какой тэг ставить.
ЗЗЫ. Я почему спрашиваю. Когда-то, довольно давно, я неплохо представлял себе работу ЦП КР580ВМ80А, который аналог i8080A. Баловался на асме, в том числе. Там всё было просто. АЛУ, который делал и математику и логику. А в современном мире мало того, что ЦП стали гораздо сложнее, так и софт очень сильно абстрагировался от железа. И мне стало совершенно немозможно понимать, что из возможностей ЦП используется софтом, как это происходит и как определить потребность в таком использовании. В области практического применения, вопрос затрагивает производительность конечного софта. В смысле, вот есть есть сейчас АМД с медленными модулями (FPU/AVX) и есть Интел с быстрыми модулями. А вот той же виртуализации qemu/kvm вообще есть дело до FPU/AVX? Оно ей не пофиг ли?
ЗЗЗЫ. Научные расчёты, обработка звука/видео, хэши/шифрование, геометрия в играх от первого и не только лица.



![]()
Что в мире софта linux использует FPU, AVX и прочие подобные инструкции?
Ответ на: комментарий от anTaRes 15.01.2016 17:36:03
Ответ на: комментарий от targitaj 15.01.2016 17:36:33
Очевидно, для ускорения сборок. (=
Различные криптоалгоритмы часто юзают AVX, при сборке ядра можно увидеть. Еще софт типа ffmpeg вроде бы (тут могу ошибаться).
Ответ на: комментарий от DeadEye 15.01.2016 17:42:52
Очевидно, для ускорения сборок. (=
не понял? как это?
Ответ на: комментарий от targitaj 15.01.2016 17:46:20
Я вообще не в теме оптимизаций и процессорных инструкций, но, по идее, если GCC собирает с оными инструкциями, то на соответствующем проце собранное прого должно бегать быстрее, чем собранное без оных.
Ответ на: комментарий от DeadEye 15.01.2016 17:54:49
если GCC собирает с оными инструкциями
может быть, ты имел ввиду, с «поддержкой оных инструкций»? Чтобы конечный софт мог их использовать?
Ответ на: комментарий от targitaj 15.01.2016 17:36:33
Я хз какой тэг ставить.
«я познаю мир»
А как вообще возможно понять надо ли это софтине?
если она написана с использованием соотв. asm-вставок - значит прям надо (ffmpeg, mplayer, *libc, эмули приставок. )
для ленивых, можно заказать соотв. оптимизации, жеж (https://twiki.cern.ch/twiki/bin/view/LHCb/VectorizeSource-code )
и в меру своих возможностей он тебе «сделает №;ись», раз уж не осилил сам в своей софтине подкрутить узкие места
либо ты гентушник, и хочешь «сделает №;ись» всей системе
как-то так
Ответ на: комментарий от anTaRes 15.01.2016 18:06:03
можно заказать соотв. оптимизации
оптимизации чего? Какие вычисления в qemu-kvm требуют задействования таких вещей?
Внезапно узнаю, что долтготянущаяся линейка SSE инструкций, каждая добавляющая десятки да так что под сотни инструкций к бедному и явно уже жутко отягощенному вопросом обратной совместимости x86, завершается на версии 4 и в моде уже новые изкаропки инструкции AVX (Advanced Vector Extensions).
Кратко ознакомился на вики, основное что меня порадовало:
Размер векторных регистров SIMD увеличивается с 128 (XMM) до 256 бит (регистры YMM0 — YMM15).
В будущем возможно расширение до 512 или 1024 бит.
Неразрушающие операции. Набор инструкций AVX позволяет использовать любую двухоперандную инструкцию XMM в трёхоперандном виде без модификации двух регистров-источников, с отдельным регистром для результата. Например, вместо a = a + b можно использовать c = a + b, при этом регистр a остаётся неизменённым.
Новая система кодирования машинных кодов VEX предоставляет новый набор префиксов кода, которые расширяют пространство возможных машинных кодов. Добавлены инструкции с количеством операндов более трёх. Векторные регистры SIMD могут быть больше 128-ми бит.
Предложено это всё еще в 2008 году, но первые процессоры с поддержкой стали выходить в 2010 (Intel, Sandy Bridge) и в 2011 (AMD, Bulldozer) годах.
Кто нибудь уже щупал?
intrinsinc-и уже есть в компиляторах gcc и MS (насчет intel не сомневаюсь)?
Вопрос чистого любопытства - интересно какова на современнейшем Intel-совместимом проце самая длинная инструкция, включая immediate данные к ней прилагающиеся, а точнее - её длина в байтах. Просто интересно.
Правка: 30 мая 2012 22:34
Блок AVX работает только без внешней видяхи. Sorry. перепутал с Quick Sync. Таки AVX работает и что-то похожее должно быть у бульдозера
Правка: 9 дек. 2011 18:42
Почему они не сделали нормальный SIMD, как на CRAY и других векторных процессорах? Т.е. когда в команде указаны адреса операндов и длина вектора?
Не было бы никакой необходимости наращивать разрядность регистров, наращивали бы число параллельных конвейеров.
PS Moondark
Вроде же двери узилища раскрылись. )
Правка: 9 дек. 2011 17:48
0iStalker
> Блок AVX работает только без внешней видяхи.
А чем это обусловлено?
laMer007
> А чем это обусловлено?
Я был не прав, - исправил изначальную реплику.
Так кто-нибудь сталкивался в программировании (особенно интересуют intrinsinc-и в MS Studio, как самой распространенной среде)? А после неё - gcc.
Правка: 9 дек. 2011 18:48
Про настольные процессоры от AMD скоро можно будет забыть, потому что AMD уходит с этого рынка на мобилки. Придётся интелу одному тянуть. А без конкуренции могут много глупостей наворотить типа всеми забытой IA64.
Moondark
> Так кто-нибудь сталкивался в программировании
Скорее всего никто, все только говорят, либо результаты отрицательные. Что касается векторных команд, то их целесообразно использовать в очень малом проценте кода, потому что сами вычисления всё равно и так выполняются быстро по сравнению с загрузкой операндов из памяти, а её никто не отменял. Да и вообще ручная низкоуровневая работа может перечеркнуть оптимизацию компилятора. Всё таки высокоуровневые языки являются декларативными по отношению к машинному коду - ты говоришь, что надо сделать, а компилятор уже сам решает как он будет этого добиваться.
Правка: 9 дек. 2011 19:50
Moondark
> Вопрос чистого любопытства - интересно какова на современнейшем Intel-совместимом проце самая длинная инструкция, включая immediate данные к ней прилагающиеся, а точнее - её длина в байтах. Просто интересно.
Максимальная вроде 17 байт.
Есть мнение, что все виды SIMD не нужны, тк почти не дают значительного прироста, ни смотря на то, что с ними нужно много повозиться.
Правка: 10 дек. 2011 16:28
laMer007
> Что конкретно это значит? Насколько ослаблены, по сравнением с тем, что было?
встречный вопрос - а что такое выравнивание данных. )
Правка: 10 дек. 2011 15:18
Главная / Новости / Intel Insider - Интервью о Haswell с Михаилом Цветковым
Intel Insider - Интервью о Haswell с Михаилом ЦветковымНовая микроархитектура семейcтва Intel ® Core™ под кодовым названием Haswell, принявшая эстафету у Ivy Bridge, создает задел для перехода на следующую технологическую норму и будет актуальной в течение нескольких ближайших лет. На ее основе планируется создание широкого спектра устройств разных классов. Не удивительно, что интерес к микроархитектуре Haswell и 4-му поколению Intel ® Core™ достаточно велик, и мы решили обсудить их особенности с Михаилом Цветковым, региональным специалистом по архитектурам Intel в России и СНГ.
— Михаил, добрый день! Давайте начнем с вопроса о том, каковы наиболее существенные отличия микроархитектуры Intel ® Core™ 4-го поколения (Haswell) от Intel ® Core™ 3-го поколения (Ivy Bridge), оказывающие влияние на производительность и функциональность?
— Микроархитектура Haswell является эволюционным развитием очень удачного семейства суперскалярных Out-Of-Order микроархитектур Intel ® Core™. Главное отличие от предыдущего поколения, я бы сказал, в увеличении размеров и эффективности ключевых структур пайплайна — Reorder Buffer (ROB), буферов Load/Store, регистрового файла и увеличении числа портов в Execution Unit, при сохранении прежних задержек конвейера, таких же, как у Sandy Bridge и Ivy Bridge. Плюс к этому были переработаны блоки предвыборки команд, блоки предсказателей и другие элементы конвейера.
К ключевым особенностям Haswell я бы отнес нацеленность на повышение IPC (Instructions per Cycle) в существующих приложениях и предоставление разработчикам новых расширений набора инструкций. Это дальнейшее развитие векторных вычислений в виде набора инструкций AVX 2.0, добавление команд для работы с битовыми полями и введение нового механизма неблокирующих транзакций (TSX).
Наибольшие изменения коснулись Execution Unit. Количество портов для исполнения микроопераций было увеличено до восьми, чтобы предоставить большую свободу планировщику при выборе отправляемых на исполнение микроопераций. Я бы еще отметил увеличение размера ROB, т.е. окна просмотра команд, которое позволяет повысить IPC за счет выборки независимых инструкций. В том, что касается поддержки расширения векторных вычислений следует отметить двукратное увеличение пропускной способности кешей второго уровня.
— Давайте поговорим про новые инструкции, появившиеся в процессорах Intel ® Core™ 4-го поколения, в частности, про AVX 2.0.
— В AVX 2.0 стоит выделить три ключевых отличия от предыдущей версии. Первое — добавлена новая инструкция Fused Multiply Add (FMA), которая объединяет в себе операции сложения и умножения. Это является ключевым действием в большинстве алгоритмов цифровой обработки сигналов — умножить на весовой коэффициент и аккумулировать полученные результат. Второе — расширение векторных 256-битных операций на целочисленные операнды и, третье, — добавление вспомогательных команд для формирования данных в векторном виде, пригодном для обработки в AVX-инструкциях.
Стоит отметить, что AVX 2.0 предоставляет очень эффективные инструменты для реализации алгоритмов обработки сигналов на процессорах Intel ® Core™ 4-го поколения. Что такое цифровая обработка с точки зрения пользователя? Это работа с видео, работа с картинками, работа со звуком, а также с большинством алгоритмов так называемого Perceptual Computing (распознавание лиц, жестов, голоса). В этих приложениях AVX 2.0 обеспечивает значительный прирост производительности и является фундаментом для дальнейшего развития нового класса приложений, для создания новых моделей использования персональных компьютеров.
— Уже имеющиеся приложения, очевидно, тоже могут получить выигрыш от использования таких команд. Насколько индустрия ПО приняла новшества, появившиеся в AVX 2.0, требуется ли существенная переработка кода, чтобы ими воспользоваться?
— У нас есть ресурс Intel Developer Zone — открытый сайт, на котором сообществу предоставлены специальные инструменты для работы с набором инструкций AVX 2.0. Начиная c программного эмулятора и заканчивая профилировщиком производительности. В частности, для анализа работы приложений может быть активно использован Intel VTune™. Сейчас мы ведем активную работу с многими производителями программного обеспечения с целью демонстрации возможностей AVX 2.0 и ускорения перевода их ресурсоемких приложений на этот новый набор инструкций.
В некоторых случаях благодаря использованию новых инструкций мы можем наблюдать рост производительности до 2 раз. В частности, это достигается за счет применения FMA, которая уменьшает число необходимых для выполнения операций умножения и сложения циклов с 8 тактов на раздельных инструкциях, например, в том же AVX 1.0, до 5 тактов в AVX 2.0. А также благодаря расширению пропускной способности кешей. Здесь мы получаем коэффициент прироста 1,6 просто за счет минимального переписывания существующего кода с раздельных инструкций Multiply и Add на использование одной инструкции FMA.
Вернемся к новым инструкциям. Наряду с AVX 2.0 стоит отметить расширения, связанные с работой с битовыми полями. Эти инструкции обеспечат прирост производительности в алгоритмах сжатия, шифрования и при обработке «сырых» данных, не выровненных на байтовые поля. Сейчас многие сигналы, многие данные, получаемые от внешних устройств, с датчиков, не обязательно являются, скажем, 8- или 16-битными. Чтобы с ними эффективно работать, будет очень востребована возможность раскладывания входного, например, 12-битного слова по полям при помощи этих новых инструкций.
Если сказать пару слов о Transactional Synchronization eXtensions (TSX), то надо, в первую очередь, отметить, что эти расширения позволяют более эффективно реализовать работу с Big Data и базами данных — в случаях, когда многие потоки обращаются к одним и тем же данным и возникают ситуации блокировки потоков. Спекулятивный доступ к данным, который реализован в TSX, позволяет эффективнее строить такие приложения и более динамично масштабировать производительность при увеличении числа параллельно исполняемых потоков за счет разрешения конфликтов при доступе к общим данным.
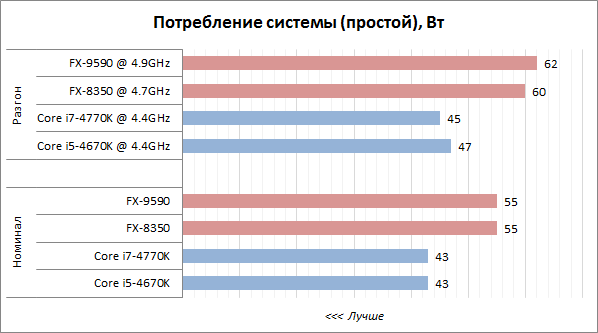
— Не раз говорилось, что процессоры Intel ® Core™ 4-го поколения разрабатывались, в первую очередь, для мобильных компьютеров. Понятно, что для таких систем важнейшим параметром является энергоэффективность, и для них существуют постоянно ужесточающиеся ограничения на TDP. Ставились ли перед разработчиками задачи «вписаться» в такие ограничения?
— Я бы сказал немного иначе. Микроархитектура Haswell создавалась с прицелом на покрытие очень широкого диапазона по Thermal Design Power (TDP): от использования в устройствах с пассивным охлаждением и требованием к рассеиваемой мощности не больше 4.5-6 Вт до использования в серверных системах, до мощных многоядерных процессоров. В клиентском сегменте процессоров максимальная TDP у 4-го поколения Intel Core достигает 84 Вт, а минимальный уровень Scenario Design Power (SDP) обеспечивается в процессорах Y-серии и сегодня составляет 4.5 Вт. Соответственно, разработчиками была решена весьма и весьма сложная инженерная задача — на одной архитектуре обеспечить создание как решений с минимальным энергопотреблением, так и высокопроизводительных процессоров для сегмента классических десктопных и серверных систем, в которых ведущую роль играет производительность, а эффективность энергопотребления становится второй по приоритету задачей.
Я считаю, что эти задачи были решены, причем решены очень хорошо. Сейчас в процессорах 4-го поколения Y-серии SDP составляет, как я уже говорил, всего 4.5 Вт, что впервые в истории Intel ® Core™ открывает возможность создания решений с пассивным, безвентиляторным охлаждением. Для компьютеров класса Ultrabook™ у нас в процессорах U-серии есть два значения TDP — 15 и 28 Вт. Для традиционного сегмента ноутбуков представлены мобильные процессоры с TDP, не превышающим 37, 47 и 57 Вт. В десктопных Intel Core 4-го поколения TDP составляет до 84 Вт, а также есть линейки десктопных процессоров S и T с пониженным энергопотреблением, предназначенные для использования в компактных системах и All-In-One, где TDP ограничена значениями 35, 45 и 65 Вт.
Еще отмечу, что в процессорах Intel ® Core™ 4-го поколения введен достаточно эффективный и интересный механизм Configurable TDP, разработан специальный Intel ® Dynamic Platform and Thermal Framework, который позволяет производителям конечных устройств самостоятельно определять границы термопакета в зависимости от примененной системы охлаждения, от режима эксплуатации выпускаемых ими устройств.
— Какие задачи планировалось решить с помощью интегрированного в процессор Fully Integrated Voltage Regulator (FIVR)? Позволяет ли он отказаться от внешнего VRM или понизить требования к нему?
— Можно сказать и так, что интегрированный регулятор напряжения решает главную задачу микроэлектроники — увеличение степени интеграции. Интегрированные регуляторы позволяют избавиться от 4 внешних регуляторов напряжения. Раньше процессору требовалось 5 стабилизированных питающих напряжений, сейчас в процессор заходит 1 питающее напряжение и еще 2 референсных на буфера DDR и PCH. Но можно считать, что на процессор, как и на достаточно простую микросхему, подается всего одно напряжение питания. Тем не менее, внешний регулятор напряжения для процессора все равно остается — который превращает входное напряжение 12 В в питающее процессор 1,8 В. Питать процессор нестабилизированным напряжением, конечно, нельзя, но теперь вместо 5 регуляторов напряжения питания остался только 1.
С одной стороны, интегрированные регулятор напряжения позволяют более эффективно управлять питанием процессора, реализуя более сложные алгоритмы Power Management. С другой стороны, они позволяют уменьшить размеры конечных устройств, предоставляя простор для их разработчиков. Упрощается дизайн материнских плат.
Сейчас, в связи с интеграцией в Y- и U-сериях Intel ® Core™ 4-го поколения контроллер чипсета (PCH) размещен под крышкой процессорного корпуса, и мы получили практически полный System-in-Package (SiP) — дизайн персонального компьютера. Можно сказать, что это сделано впервые в истории процессоров такого класса. Естественно, что с интеграцией основных компонент требуется оптимизация вспомогательных подсистем, в частности, подсистемы питания.
— Токи питания процессора достаточно серьезные, на регуляторах напряжения рассеивается ощутимая мощность (не зря для них на топовых материнских платах организуется радиаторное охлаждение с обдувом от процессорного вентилятора). Как сказывается наличие FIVR на общем TDP процессора? Не опасно ли соседство на одном кристалле, скажем так, «силовой части» микросхемы с кеш-памятью и другими блоками процессора?
— Гениальность разработчиков как раз в том и состоит, что они решили эту непростую инженерную задачу, не пожертвовав ни какой функциональной или вычислительной частью системы. Несмотря на значительные изменения в подсистеме питания, связанные с интеграцией на кристалл регуляторов напряжения, мы не наблюдаем никаких ухудшений остальных характеристик системы.
Если обсуждать энергопотребление, то с ростом степени интеграции надо говорить об энергопотреблении платформы в целом, а не только одного процессора. Надо понимать, что означают величины TDP для отдельных компонент, и как они сказываются на характеристиках всей системы с пользовательской точки зрения.
Например, в U-сериях Intel ® Core™ 3-го и 4-го поколений TDP у процессоров на микроархитектуре Ivy Bridge составлял 17 Вт, а у более высокоинтегрированного процессора на микроархитектуре Haswell — 15Вт. Казалось бы, разница всего 2 Вт, не очень большое достижение. Но платформенное энергопотребление у Ivy Bridge должно включать в себя энергопотребление чипсета, а это плюс еще 3 Вт, получается 20 Вт. У процессоров U-серии Haswell энергопотребление вместе с интегрированным под крышку чипсетом 15 Вт, то есть только на этом уже имеет место 25% улучшение энергоэффективности платформы. А ведь в случае Ivy Bridge мы еще не учитывали рассеивание на внешних регуляторах напряжения. И так как у нас сейчас благодаря интеграции практически вся платформа включена в корпус процессора U-серии, то при сравнениях с процессорами предыдущих поколений следует рассматривать для последних не только TDP процессоров, а мощность, рассеиваемую всей платформой, с учетом внешних компонент.
— В Intel ® Core™ 4-го поколения доступны несколько версий встроенных графических контроллеров, в чем заключаются различия между ними и насколько они велики?
— Графика — это еще одно большое, даже революционное изменение в 4-м поколении Intel ® Core™. В старших моделях встроенной графики GT3 с обозначениями HD 5100 и 5200 произошел двукратный, если сравнивать с GT2/HD 4000, скачок по производительности, что позволяет теперь говорить о встроенной графике, как об абсолютно полноценном решении, в том числе и для игровых задач.
В то же время, графика GT2, то есть HD 4000, подверглась эволюционным изменениям, получив индекс HD 4600. Например, 16 исполнительных блоков в HD 4000 процессоров микроархитектуры Ivy Bridge теперь заменены 20 исполнительными блоками в процессорах Haswell, что сопровождается соответствующим ростом производительности. Были также оптимизированы блоки Quick Sync Video, что дало заметный прирост производительности при обработке мультимедиа. Далее, в графической подсистеме добавлена поддержка DisplayPort 1.2 с Multistream, стало возможным подключение дисплеев с суммарным разрешением 4Кх2К через 1 порт.
Что касается графики с кодовым обозначением GT3, то тут изменения глобальны. Впервые в истории Intel встроенная графика получила собственное имя — Iris™ для HD 5100 и Iris™ Pro для HD 5200 со специализированной EDRAM-памятью, размещенной внутри процессорного корпуса. Графика Iris™ Pro дает уже реальную возможность в большинстве случаев полностью отказаться от дискретных решений.
Что касается технических характеристик, то максимальные динамические частоты для встроенной графики остаются на прежнем уровне, порядка 1,1—1,2 ГГц. Память так же разделяется до 1,7 ГБ на нужды графики, а в Iris™ Pro появилась внутренняя память объемом до 128 МБ (в зависимости от модели процессора), работающая в режиме L4-кеша, предназначенная для ускорения обработки буфера и минимизации трафика с внешней DDR-памятью. Это решение со специализированной встроенной памятью позволяет как повысить производительность графического ядра, так и понизить суммарное энергопотребление платформы.
— Мобильные процессоров Intel ® Core™ 4-го поколения, получается, охватывают достаточно широкий спектр устройств, и сами они заметно отличаются друг от друга. Как в этом разобраться? И что представляет собой интегрированный PCH?
— Семейство мобильных процессоров Intel ® Core™ 4-го поколения состоит из 4 линеек. Первые две — это модели с суффиксами U и Y. Они представляют собой решения, в которых используется интегрированный чипсет Lynx Point, он находится под крышкой корпуса процессора. Еще две линейки — M и H — предназначены для классических двухчиповых решений, в которых процессор и PCH-контроллер чипсета размещены в отдельных корпусах. Процессоры серий M и H имеют больший TDP, они ориентированы на применение в ноутбуках классического форм-фактора и премиум-сегменте ноутбуков для энтузиастов (линейка H со встроенной графикой Intel Iris™ Pro). Если процессоры U и Y будут выпускаться только двухъядерными, то H — только четырехъядерными, а M — и двух-, и четырехъядерными. Корпуса у процессоров M будут сокетными, rPGA (reduced pitch Pin Grid Array (rPGA), а у H-процессоров — FCBGA (Ball Grid Array). Процессоры U со встроенной графической подсистемой Intel Iris™, а также Y, ориентированные на применение в Ultrabook™ с отсоединяемым дисплеем и в старших моделях планшетов, будут выпускаться только в виде одночиповых решений с FCBGA-корпусами.
Что касается PCH-контроллера чипсета Lynx Point, то его функционал не претерпел глобальных изменений. Это работа с портами ввода-вывода (USB 3.0, SATA 3.0, PCI Express) плюс ME (Management Engine) и обеспечение работы центрального процессора. Есть, впрочем, некоторые доработки. В двухчиповых системаx (десктопы и мобильные M-/H-линейки) из процессора в PCH перенесли VGA-порт, а в сериях U и Y в хаб PCH добавили необходимые для мобильных устройств контроллеры сенсоров, совсем убрав из этих систем VGA-порт.
Кстати, последнее стоит немного пояснить. В десктопных платформах на Intel ® Core™ 4-го поколения и чипсетах 8-го поколения старый добрый VGA остался, но теперь он реализован в микросхеме PCH-контроллера, а не в процессоре. В интегрированных в U- и Y-процессоры контроллерах PCH порт VGA исключен — таким образом, из Ultrabook™ и планшетов он уходит окончательно.
— Кстати, с появлением новых процессоров для Utrabook™ что-то изменилось в спецификации, в требованиях к этим компьютерам?
— Спецификация Ultrabook™ на платформе Shark Bay Refresh предполагает следующие ключевые моменты:
• Толщина менее 21 мм для систем с диагональю 14 дюймов и больше; 18 мм и менее для систем с диагональю экрана до 14 дюймов.
• Наличие процессора Intel ® Core™ 4-го поколения серии U или Y.
• Наличие сенсорного дисплея.
• Готовность аппаратных средств к использованию Voice Command, т.е. двухмикрофонный дизайн с хорошим шумоподавлением, обеспечивающий хорошую сепарацию и оцифровку голоса. Полная поддержка будет вводиться по мере готовности программной части для различных языков.
• Наличие камеры разрешением, как минимум, 720p; желательно — с разрешением Full HD.
• Крайне желательно наличие дисплея Full HD c поддержкой технологии Self Refresh.
• Обязательна поддержка Wi-Fi 802.11n; желательно иметь поддержку нового стандарта Wi-Fi 802.11ac.
• Обязательна поддержка WiDi.
• Желательна поддержка технологии NFC.
Технология NFC будет развиваться, ее поддержка будет во многом определять впечатления пользователей от работы на новых Ultrabook™. Будет развиваться также Intel Common Connectivity Framework, который позволит устройствам на базе платформы Intel соединяться и обмениваться файлами через все доступные коммуникационные каналы — Bluetooth, Wi-Fi, NFC и т.д. В Ultrabook™ 2013 года ожидается появление Common Connectivity Framework 2.0.
В связи с повышением энергоэффективности новой платформы тоже есть изменения. Так, Ultrabook™ должен быть способен находиться в режиме Connected Standby более 7 дней. Под управлением Windows 8 в режиме Idle работа от батареи должна длиться не меньше 9 часов, время проигрывания видео Full HD должно составлять не менее 6 часов (рекомендуется 9 часов).